Trendy workflows showcase the infinite prospects of generative and agentic AI on PCs.
Of many, some examples embody tuning a chatbot to deal with product-support questions or constructing a private assistant for managing one’s schedule. A problem stays, nevertheless, in getting a small language mannequin to reply constantly with excessive accuracy for specialised agentic duties.
That’s the place fine-tuning is available in.
Unsloth, one of many world’s most generally used open-source frameworks for fine-tuning LLMs, gives an approachable strategy to customise fashions. It’s optimized for environment friendly, low-memory coaching on NVIDIA GPUs — from GeForce RTX desktops and laptops to RTX PRO workstations and DGX Spark, the world’s smallest AI supercomputer.
One other highly effective place to begin for fine-tuning is the just-announced NVIDIA Nemotron 3 household of open fashions, information and libraries. Nemotron 3 introduces probably the most environment friendly household of open fashions, very best for agentic AI fine-tuning.
Instructing AI New Tips
Effective-tuning is like giving an AI mannequin a centered coaching session. With examples tied to a selected subject or workflow, the mannequin improves its accuracy by studying new patterns and adapting to the duty at hand.
Selecting a fine-tuning methodology for a mannequin depends upon how a lot of the unique mannequin the developer desires to regulate. Primarily based on their objectives, builders can use considered one of three predominant fine-tuning strategies:
Parameter-efficient fine-tuning (reminiscent of LoRA or QLoRA):
- The way it works: Updates solely a small portion of the mannequin for quicker, lower-cost coaching. It’s a wiser and environment friendly strategy to improve a mannequin with out altering it drastically.
- Goal use case: Helpful throughout practically all eventualities the place full fine-tuning would historically be utilized — together with including area information, enhancing coding accuracy, adapting the mannequin for authorized or scientific duties, refining reasoning, or aligning tone and conduct.
- Necessities: Small- to medium-sized dataset (100-1,000 prompt-sample pairs).
Full fine-tuning:
- The way it works: Updates the entire mannequin’s parameters — helpful for educating the mannequin to comply with particular codecs or kinds.
- Goal use case: Superior use circumstances, reminiscent of constructing AI brokers and chatbots that should present help a few particular subject, keep inside a sure set of guardrails and reply in a specific method.
- Necessities: Giant dataset (1,000+ prompt-sample pairs).
Reinforcement studying:
- The way it works: Adjusts the conduct of the mannequin utilizing suggestions or choice alerts. The mannequin learns by interacting with its atmosphere and makes use of the suggestions to enhance itself over time. It is a complicated, superior method that interweaves coaching and inference — and can be utilized in tandem with parameter-efficient fine-tuning and full fine-tuning strategies. See Unsloth’s Reinforcement Studying Information for particulars.
- Goal use case: Bettering the accuracy of a mannequin in a specific area — reminiscent of regulation or drugs — or constructing autonomous brokers that may orchestrate actions on a consumer’s behalf.
- Necessities: A course of that accommodates an motion mannequin, a reward mannequin and an atmosphere for the mannequin to study from.
One other issue to think about is the VRAM required per every methodology. The chart beneath gives an summary of the necessities to run every sort of fine-tuning methodology on Unsloth.
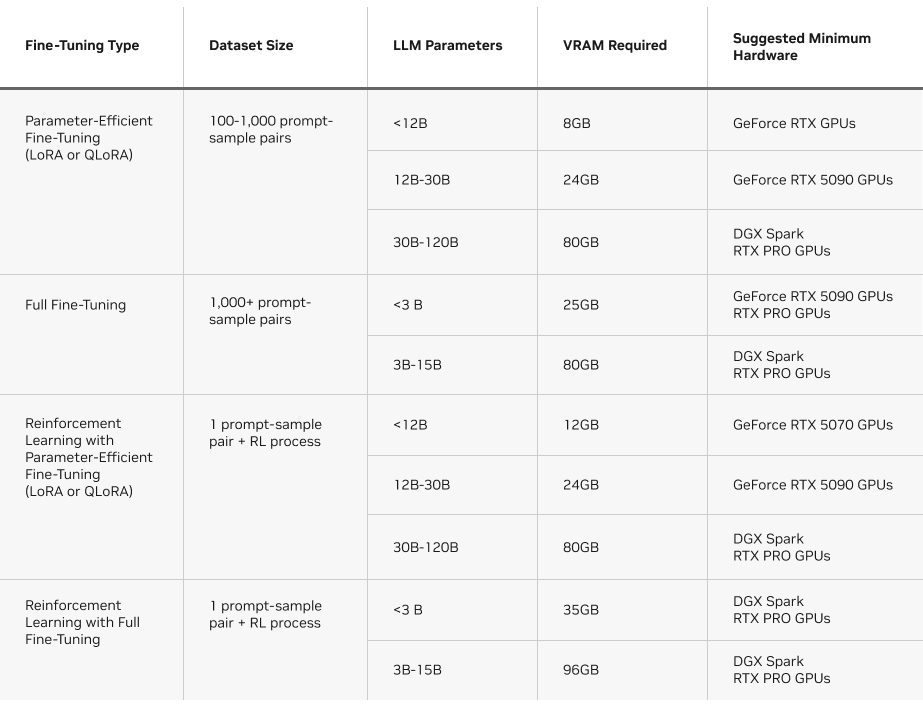
Unsloth: A Quick Path to Effective-Tuning on NVIDIA GPUs
LLM fine-tuning is a memory- and compute-intensive workload that entails billions of matrix multiplications to replace mannequin weights at each coaching step. The sort of heavy parallel workload requires the ability of NVIDIA GPUs to finish the method shortly and effectively.
Unsloth shines at this workload, translating complicated mathematical operations into environment friendly, customized GPU kernels to speed up AI coaching.
Unsloth helps enhance the efficiency of the Hugging Face transformers library by 2.5x on NVIDIA GPUs. These GPU-specific optimizations, mixed with Unsloth’s ease of use, make fine-tuning accessible to a broader group of AI fanatics and builders.
The framework is constructed and optimized for NVIDIA {hardware} — from GeForce RTX laptops to RTX PRO workstations and DGX Spark — offering peak efficiency whereas lowering VRAM consumption.
Unsloth gives useful guides on get began and handle completely different LLM configurations, hyperparameters and choices, together with instance notebooks and step-by-step workflows.
Try a few of these Unsloth guides:
Learn to set up Unsloth on NVIDIA DGX Spark. Learn the NVIDIA technical weblog for a deep dive of fine-tuning and reinforcement studying on the NVIDIA Blackwell platform.
For a hands-on native fine-tuning walkthrough, watch Matthew Berman displaying reinforcement studying working on a NVIDIA GeForce RTX 5090 utilizing Unsloth within the video beneath.
Accessible Now: NVIDIA Nemotron 3 Household of Open Fashions
The brand new Nemotron 3 household of open fashions — in Nano, Tremendous, and Extremely sizes — constructed on a brand new hybrid latent Combination-of-Specialists (MoE) structure, introduces probably the most environment friendly household of open fashions with main accuracy, very best for constructing agentic AI purposes.
Nemotron 3 Nano 30B-A3B, out there now, is probably the most compute-efficient mannequin within the lineup. It’s optimized for duties reminiscent of software program debugging, content material summarization, AI assistant workflows and data retrieval at low inference prices. Its hybrid MoE design delivers:
- As much as 60% fewer reasoning tokens, considerably lowering inference price.
- A 1 million-token context window, permitting the mannequin to retain way more data for lengthy, multistep duties.
Nemotron 3 Tremendous is a high-accuracy reasoning mannequin for multi-agent purposes, whereas Nemotron 3 Extremely is for complicated AI purposes. Each are anticipated to be out there within the first half of 2026.
NVIDIA additionally launched immediately an open assortment of coaching datasets and state-of-the-art reinforcement studying libraries. Nemotron 3 Nano fine-tuning is obtainable on Unsloth.
Obtain Nemotron 3 Nano now from Hugging Face, or experiment with it by Llama.cpp and LM Studio.
DGX Spark: A Compact AI Powerhouse
DGX Spark allows native fine-tuning and brings unimaginable AI efficiency in a compact, desktop supercomputer, giving builders entry to extra reminiscence than a typical PC.
Constructed on the NVIDIA Grace Blackwell structure, DGX Spark delivers as much as a petaflop of FP4 AI efficiency and contains 128GB of unified CPU-GPU reminiscence, giving builders sufficient headroom to run bigger fashions, longer context home windows and extra demanding coaching workloads regionally.
For fine-tuning, DGX Spark allows:
- Bigger mannequin sizes. Fashions with greater than 30 billion parameters usually exceed the VRAM capability of shopper GPUs however match comfortably inside DGX Spark’s unified reminiscence.
- Extra superior strategies. Full fine-tuning and reinforcement-learning-based workflows — which demand extra reminiscence and better throughput — run considerably quicker on DGX Spark.
- Native management with out cloud queues. Builders can run compute-heavy duties regionally as a substitute of ready for cloud cases or managing a number of environments.
DGX Spark’s strengths transcend LLMs. Excessive-resolution diffusion fashions, for instance, usually require extra reminiscence than a typical desktop can present. With FP4 assist and huge unified reminiscence, DGX Spark can generate 1,000 photographs in only a few seconds and maintain greater throughput for artistic or multimodal pipelines.
The desk beneath reveals efficiency for fine-tuning the Llama household of fashions on DGX Spark.

As fine-tuning workflows advance, the brand new Nemotron 3 household of open fashions supply scalable reasoning and long-context efficiency optimized for RTX techniques and DGX Spark.
Be taught extra about how DGX Spark allows intensive AI duties.
#ICYMI — The Newest Developments in NVIDIA RTX AI PCs
🚀 FLUX.2 Picture-Technology Fashions Now Launched, Optimized for NVIDIA RTX GPUs
The brand new fashions from Black Forest Labs can be found in FP8 quantizations that cut back VRAM and improve efficiency by 40%.
✨ Nexa.ai Expands Native AI on RTX PCs With Hyperlink for Agentic Search
The brand new on-device search agent delivers 3x quicker retrieval-augmented era indexing and 2x quicker LLM inference, indexing a dense 1GB folder from about quarter-hour to only 4 to 5 minutes. Plus, DeepSeek OCR now runs regionally in GGUF by way of NexaSDK, providing plug-and-play parsing of charts, formulation and multilingual PDFs on RTX GPUs.
🤝Mistral AI Unveils New Mannequin Household Optimized for NVIDIA GPUs
The brand new Mistral 3 fashions are optimized from cloud to edge and out there for quick, native experimentation by Ollama and Llama.cpp.
🎨Blender 5.0 Lands With HDR Shade and Main Efficiency Positive factors
The discharge provides ACES 2.0 wide-gamut/HDR colour, NVIDIA DLSS for as much as 5x quicker hair and fur rendering, higher dealing with of large geometry, and movement blur for Grease Pencil.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC publication. Comply with NVIDIA Workstation on LinkedIn and X.
See discover relating to software program product data.