How NVIDIA’s AI manufacturing facility platform balances most efficiency and minimal latency, optimizing AI inference to energy the subsequent industrial revolution.
Once we immediate generative AI to reply a query or create a picture, massive language fashions generate tokens of intelligence that mix to offer the consequence.
One immediate. One set of tokens for the reply. That is known as AI inference.
Agentic AI makes use of reasoning to finish duties. AI brokers aren’t simply offering one-shot solutions. They break duties down right into a sequence of steps, every one a unique inference approach.
One immediate. Many units of tokens to finish the job.
The engines of AI inference are known as AI factories — large infrastructures that serve AI to thousands and thousands of customers directly.
AI factories generate AI tokens. Their product is intelligence. Within the AI period, this intelligence grows income and earnings. Rising income over time is dependent upon how environment friendly the AI manufacturing facility might be because it scales.
AI factories are the machines of the subsequent industrial revolution.

Aerial view of Crusoe (Stargate)
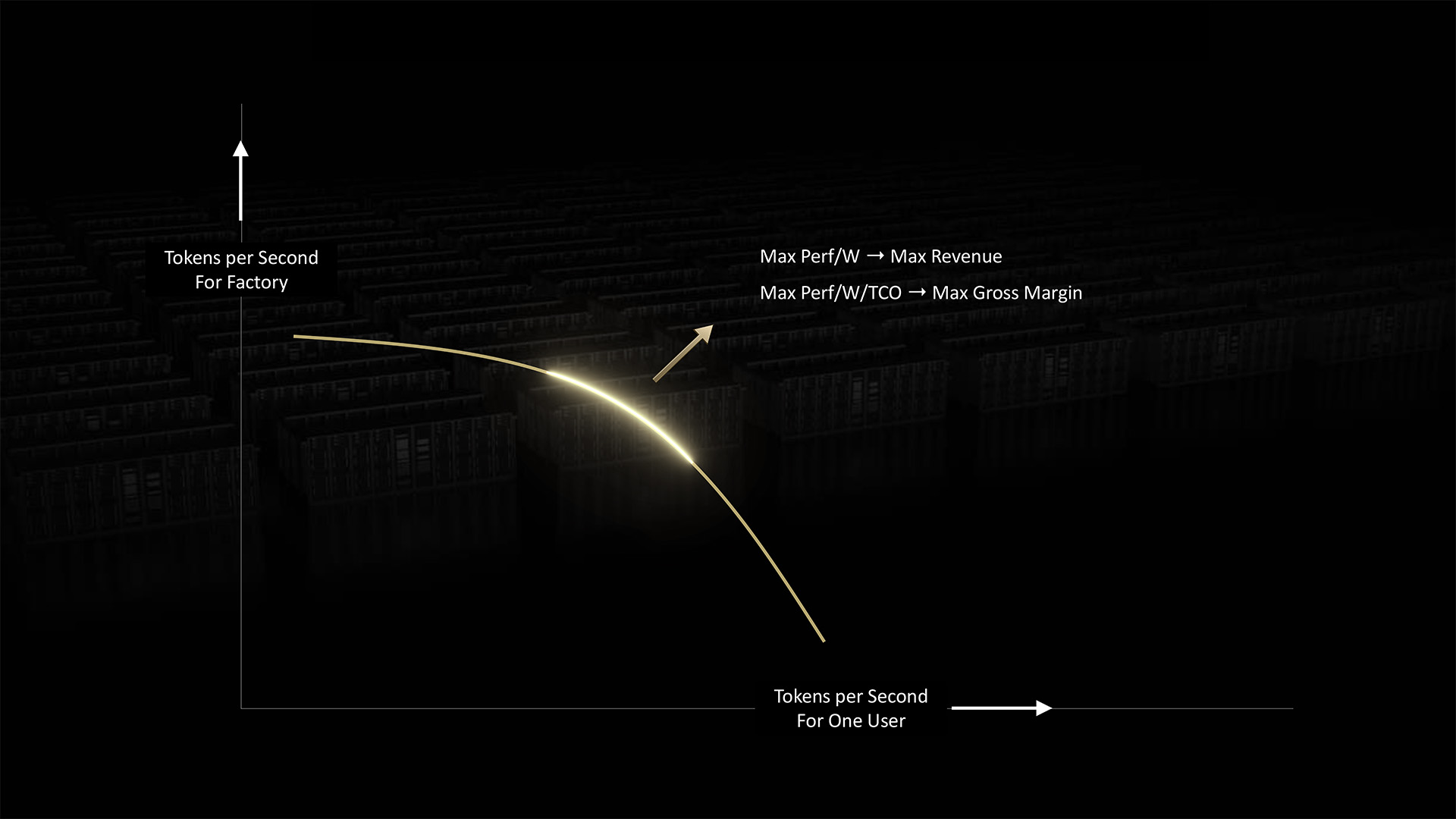
AI factories must stability two competing calls for to ship optimum inference: pace per person and general system throughput.

CoreWeave, 200MW, USA, scaling globally
AI factories can enhance each components by scaling — to extra FLOPS and better bandwidth. They’ll group and course of AI workloads to maximise productiveness.
However in the end, AI factories are restricted by the facility they will entry.
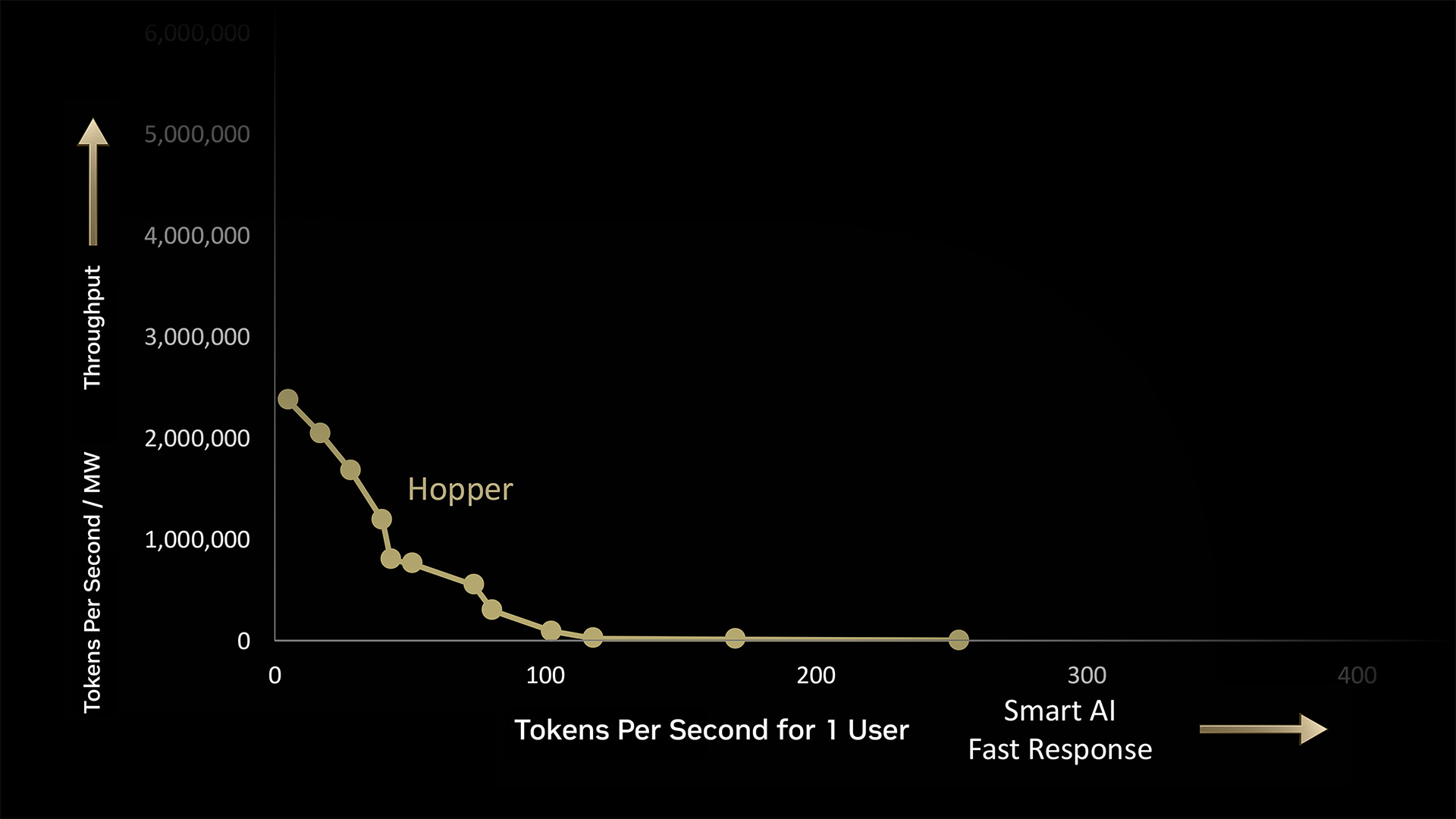
In a 1-megawatt AI manufacturing facility, NVIDIA Hopper generates 180,000 tokens per second (TPS) at max quantity, or 225 TPS for one person on the quickest.
However the actual work occurs within the house in between. Every dot alongside the curve represents batches of workloads for the AI manufacturing facility to course of — every with its personal mixture of efficiency calls for.
NVIDIA GPUs have the flexibleness to deal with this full spectrum of workloads as a result of they are often programmed utilizing NVIDIA CUDA software program.
The NVIDIA Blackwell structure can do way more with 1 megawatt than the Hopper structure — and there’s extra coming. Optimizing the software program and {hardware} stacks means Blackwell will get sooner and extra environment friendly over time.
Blackwell will get one other increase when builders optimize the AI manufacturing facility workloads autonomously with NVIDIA Dynamo, the brand new working system for AI factories.
Dynamo breaks inference duties into smaller parts, dynamically routing and rerouting workloads to essentially the most optimum compute assets obtainable at that second.
The enhancements are outstanding. In a single generational leap of processor structure from Hopper to Blackwell, we will obtain a 50x enchancment in AI reasoning efficiency utilizing the identical quantity of vitality.
That is how NVIDIA full-stack integration and superior software program give prospects large pace and effectivity boosts within the time between chip structure generations.
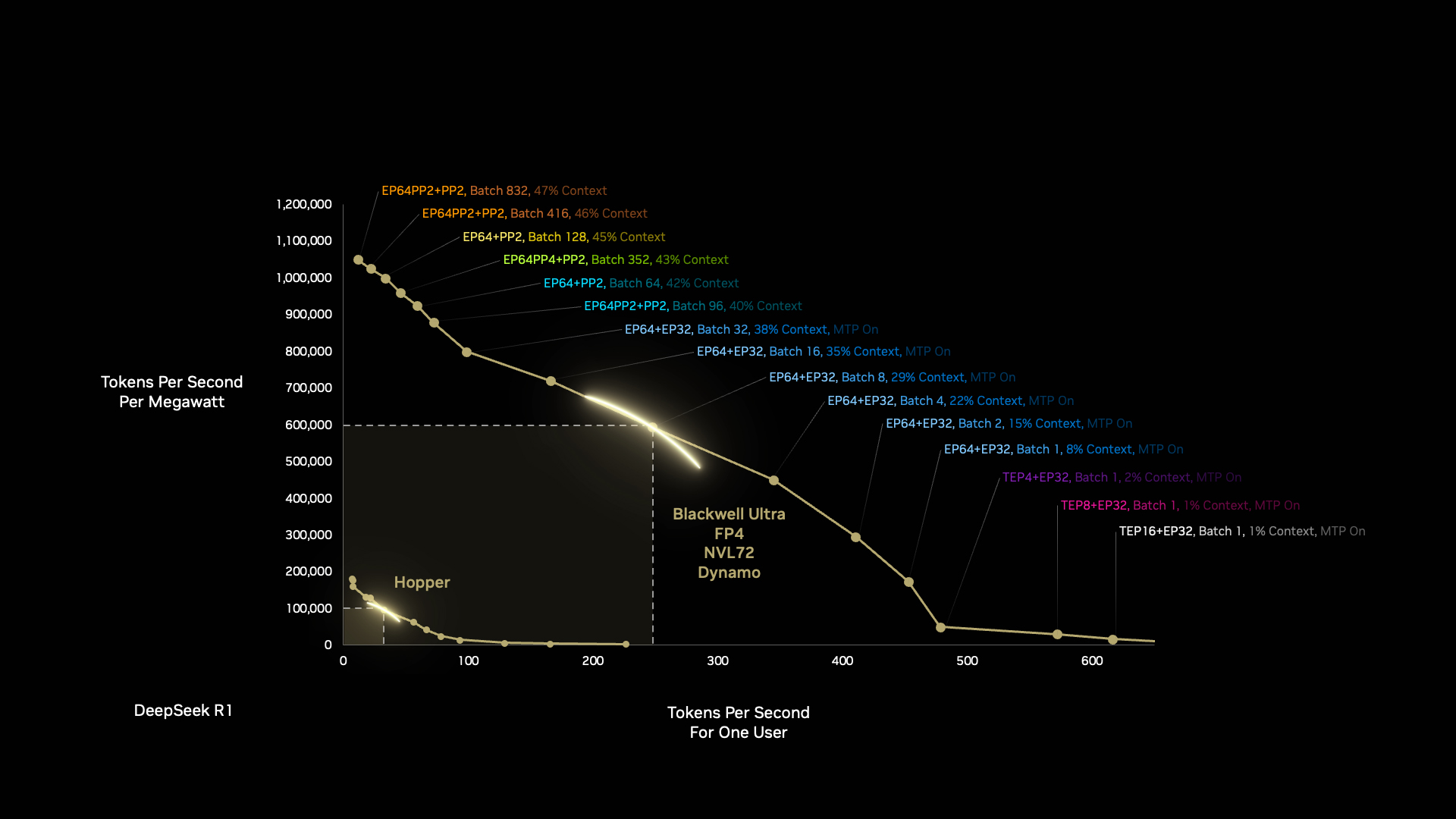
We push this curve outward with every era, from {hardware} to software program, from compute to networking.
And with every push ahead in efficiency, AI can create trillions of {dollars} of productiveness for NVIDIA’s companions and prospects across the globe — whereas bringing us one step nearer to curing illnesses, reversing local weather change and uncovering a few of the best secrets and techniques of the universe.
That is compute turning into capital — and progress.