Editor’s word: This submit is a part of the AI Decoded sequence, which demystifies AI by making the know-how extra accessible and showcases new {hardware}, software program, instruments and accelerations for NVIDIA RTX PC and workstation customers.
The demand for instruments to simplify and optimize generative AI improvement is skyrocketing. Purposes primarily based on retrieval-augmented era (RAG) — a way for enhancing the accuracy and reliability of generative AI fashions with information fetched from specified exterior sources — and customised fashions are enabling builders to tune AI fashions to their particular wants.
Whereas such work might have required a posh setup up to now, new instruments are making it simpler than ever.
NVIDIA AI Workbench simplifies AI developer workflows by serving to customers construct their very own RAG tasks, customise fashions and extra. It’s a part of the RTX AI Toolkit — a collection of instruments and software program improvement kits for customizing, optimizing and deploying AI capabilities — launched at COMPUTEX earlier this month. AI Workbench removes the complexity of technical duties that may derail specialists and halt learners.
What Is NVIDIA AI Workbench?
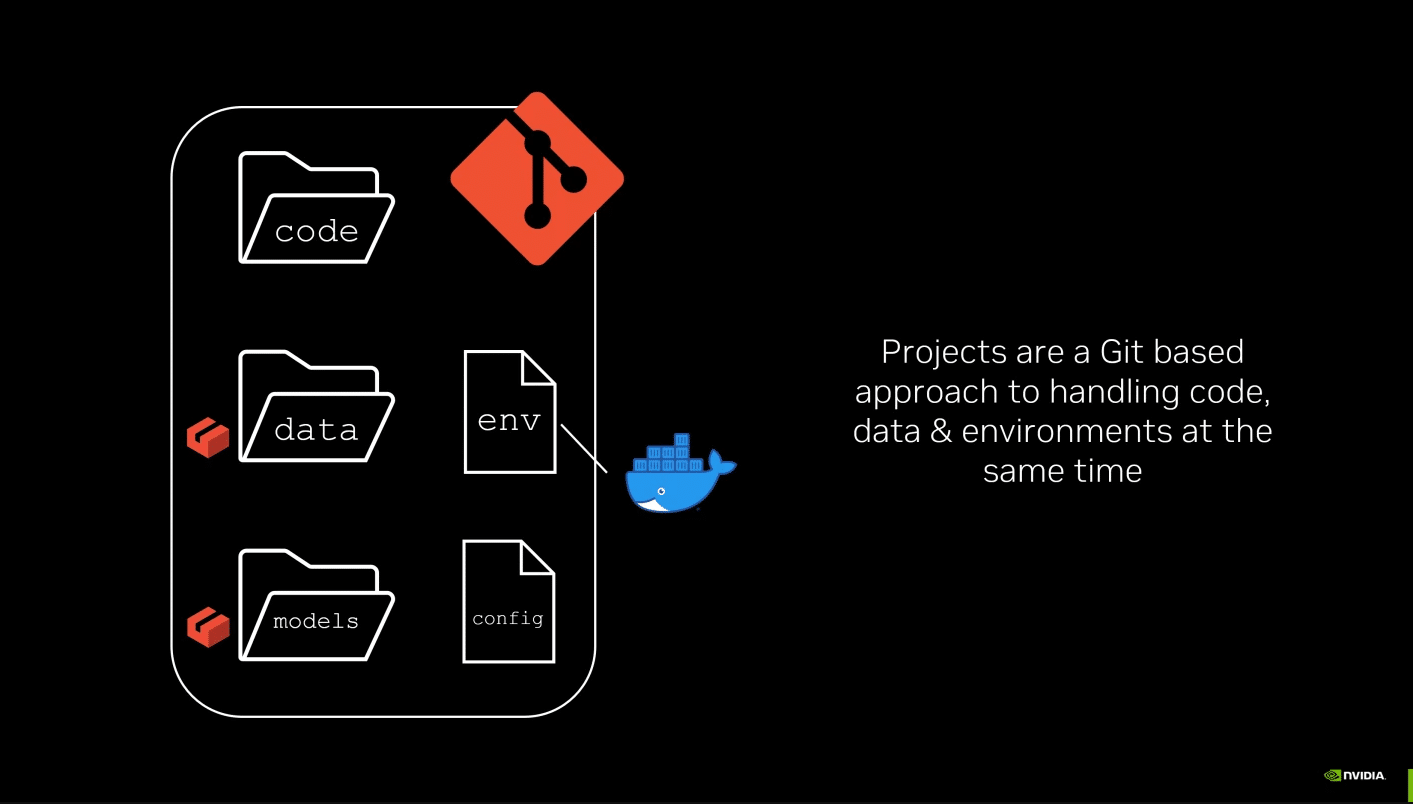
Accessible without spending a dime, NVIDIA AI Workbench permits customers to develop, experiment with, check and prototype AI purposes throughout GPU techniques of their selection — from laptops and workstations to knowledge middle and cloud. It presents a brand new strategy for creating, utilizing and sharing GPU-enabled improvement environments throughout folks and techniques.
A easy set up will get customers up and operating with AI Workbench on an area or distant machine in simply minutes. Customers can then begin a brand new undertaking or replicate one from the examples on GitHub. All the pieces works by way of GitHub or GitLab, so customers can simply collaborate and distribute work. Be taught extra about getting began with AI Workbench.
How AI Workbench Helps Deal with AI Venture Challenges
Creating AI workloads can require guide, usually complicated processes, proper from the beginning.
Establishing GPUs, updating drivers and managing versioning incompatibilities might be cumbersome. Reproducing tasks throughout totally different techniques can require replicating guide processes again and again. Inconsistencies when replicating tasks, like points with knowledge fragmentation and model management, can hinder collaboration. Diverse setup processes, transferring credentials and secrets and techniques, and modifications within the atmosphere, knowledge, fashions and file areas can all restrict the portability of tasks.
AI Workbench makes it simpler for knowledge scientists and builders to handle their work and collaborate throughout heterogeneous platforms. It integrates and automates numerous features of the event course of, providing:
- Ease of setup: AI Workbench streamlines the method of establishing a developer atmosphere that’s GPU-accelerated, even for customers with restricted technical information.
- Seamless collaboration: AI Workbench integrates with version-control and project-management instruments like GitHub and GitLab, lowering friction when collaborating.
- Consistency when scaling from native to cloud: AI Workbench ensures consistency throughout a number of environments, supporting scaling up or down from native workstations or PCs to knowledge facilities or the cloud.
RAG for Paperwork, Simpler Than Ever
NVIDIA presents pattern improvement Workbench Tasks to assist customers get began with AI Workbench. The hybrid RAG Workbench Venture is one instance: It runs a customized, text-based RAG net software with a person’s paperwork on their native workstation, PC or distant system.
Each Workbench Venture runs in a “container” — software program that features all the required elements to run the AI software. The hybrid RAG pattern pairs a Gradio chat interface frontend on the host machine with a containerized RAG server — the backend that providers a person’s request and routes queries to and from the vector database and the chosen massive language mannequin.
This Workbench Venture helps all kinds of LLMs out there on NVIDIA’s GitHub web page. Plus, the hybrid nature of the undertaking lets customers choose the place to run inference.
Builders can run the embedding mannequin on the host machine and run inference regionally on a Hugging Face Textual content Era Inference server, heading in the right direction cloud assets utilizing NVIDIA inference endpoints just like the NVIDIA API catalog, or with self-hosting microservices equivalent to NVIDIA NIM or third-party providers.
The hybrid RAG Workbench Venture additionally contains:
- Efficiency metrics: Customers can consider how RAG- and non-RAG-based person queries carry out throughout every inference mode. Tracked metrics embody Retrieval Time, Time to First Token (TTFT) and Token Velocity.
- Retrieval transparency: A panel exhibits the precise snippets of textual content — retrieved from probably the most contextually related content material within the vector database — which can be being fed into the LLM and enhancing the response’s relevance to a person’s question.
- Response customization: Responses might be tweaked with quite a lot of parameters, equivalent to most tokens to generate, temperature and frequency penalty.
To get began with this undertaking, merely set up AI Workbench on an area system. The hybrid RAG Workbench Venture might be introduced from GitHub into the person’s account and duplicated to the native system.
Extra assets can be found within the AI Decoded person information. As well as, group members present useful video tutorials, just like the one from Joe Freeman beneath.
Customise, Optimize, Deploy
Builders usually search to customise AI fashions for particular use circumstances. High-quality-tuning, a way that modifications the mannequin by coaching it with extra knowledge, might be helpful for model switch or altering mannequin habits. AI Workbench helps with fine-tuning, as effectively.
The Llama-factory AI Workbench Venture permits QLoRa, a fine-tuning technique that minimizes reminiscence necessities, for quite a lot of fashions, in addition to mannequin quantization by way of a easy graphical person interface. Builders can use public or their very own datasets to fulfill the wants of their purposes.
As soon as fine-tuning is full, the mannequin might be quantized for improved efficiency and a smaller reminiscence footprint, then deployed to native Home windows purposes for native inference or to NVIDIA NIM for cloud inference. Discover a full tutorial for this undertaking on the NVIDIA RTX AI Toolkit repository.
Actually Hybrid — Run AI Workloads Wherever
The Hybrid-RAG Workbench Venture described above is hybrid in a couple of manner. Along with providing a selection of inference mode, the undertaking might be run regionally on NVIDIA RTX workstations and GeForce RTX PCs, or scaled as much as distant cloud servers and knowledge facilities.
The power to run tasks on techniques of the person’s selection — with out the overhead of establishing the infrastructure — extends to all Workbench Tasks. Discover extra examples and directions for fine-tuning and customization within the AI Workbench quick-start information.
Generative AI is reworking gaming, videoconferencing and interactive experiences of every kind. Make sense of what’s new and what’s subsequent by subscribing to the AI Decoded e-newsletter.