As AI use instances proceed to increase — from doc summarization to customized software program brokers — builders and lovers are in search of sooner, extra versatile methods to run massive language fashions (LLMs).
Operating fashions domestically on PCs with NVIDIA GeForce RTX GPUs permits high-performance inference, enhanced knowledge privateness and full management over AI deployment and integration. Instruments like LM Studio — free to strive — make this doable, giving customers a straightforward technique to discover and construct with LLMs on their very own {hardware}.
LM Studio has develop into one of the vital broadly adopted instruments for native LLM inference. Constructed on the high-performance llama.cpp runtime, the app permits fashions to run completely offline and can even function OpenAI-compatible software programming interface (API) endpoints for integration into customized workflows.
The discharge of LM Studio 0.3.15 brings improved efficiency for RTX GPUs due to CUDA 12.8, considerably enhancing mannequin load and response instances. The replace additionally introduces new developer-focused options, together with enhanced device use through the “tool_choice” parameter and a redesigned system immediate editor.
The most recent enhancements to LM Studio enhance its efficiency and value — delivering the best throughput but on RTX AI PCs. This implies sooner responses, snappier interactions and higher instruments for constructing and integrating AI domestically.
The place On a regular basis Apps Meet AI Acceleration
LM Studio is constructed for flexibility — fitted to each informal experimentation or full integration into customized workflows. Customers can work together with fashions by way of a desktop chat interface or allow developer mode to serve OpenAI-compatible API endpoints. This makes it simple to attach native LLMs to workflows in apps like VS Code or bespoke desktop brokers.
For instance, LM Studio may be built-in with Obsidian, a well-liked markdown-based information administration app. Utilizing community-developed plug-ins like Textual content Generator and Sensible Connections, customers can generate content material, summarize analysis and question their very own notes — all powered by native LLMs working by way of LM Studio. These plug-ins join on to LM Studio’s native server, enabling quick, personal AI interactions with out counting on the cloud.
The 0.3.15 replace provides new developer capabilities, together with extra granular management over device use through the “tool_choice” parameter and an upgraded system immediate editor for dealing with longer or extra complicated prompts.
The tool_choice parameter lets builders management how fashions interact with exterior instruments — whether or not by forcing a device name, disabling it completely or permitting the mannequin to resolve dynamically. This added flexibility is very beneficial for constructing structured interactions, retrieval-augmented era (RAG) workflows or agent pipelines. Collectively, these updates improve each experimentation and manufacturing use instances for builders constructing with LLMs.
LM Studio helps a broad vary of open fashions — together with Gemma, Llama 3, Mistral and Orca — and quite a lot of quantization codecs, from 4-bit to full precision.
Widespread use instances span RAG, multi-turn chat with lengthy context home windows, document-based Q&A and native agent pipelines. And by utilizing native inference servers powered by the NVIDIA RTX-accelerated llama.cpp software program library, customers on RTX AI PCs can combine native LLMs with ease.
Whether or not optimizing for effectivity on a compact RTX-powered system or maximizing throughput on a high-performance desktop, LM Studio delivers full management, pace and privateness — all on RTX.
Expertise Most Throughput on RTX GPUs
On the core of LM Studio’s acceleration is llama.cpp — an open-source runtime designed for environment friendly inference on client {hardware}. NVIDIA partnered with the LM Studio and llama.cpp communities to combine a number of enhancements to maximise RTX GPU efficiency.
Key optimizations embody:
- CUDA graph enablement: Teams a number of GPU operations right into a single CPU name, lowering CPU overhead and enhancing mannequin throughput by as much as 35%.
- Flash consideration CUDA kernels: Boosts throughput by as much as 15% by enhancing how LLMs course of consideration — a vital operation in transformer fashions. This optimization permits longer context home windows with out growing reminiscence or compute necessities.
- Help for the newest RTX architectures: LM Studio’s replace to CUDA 12.8 ensures compatibility with the total vary of RTX AI PCs — from GeForce RTX 20 Collection to NVIDIA Blackwell-class GPUs, giving customers the pliability to scale their native AI workflows from laptops to high-end desktops.
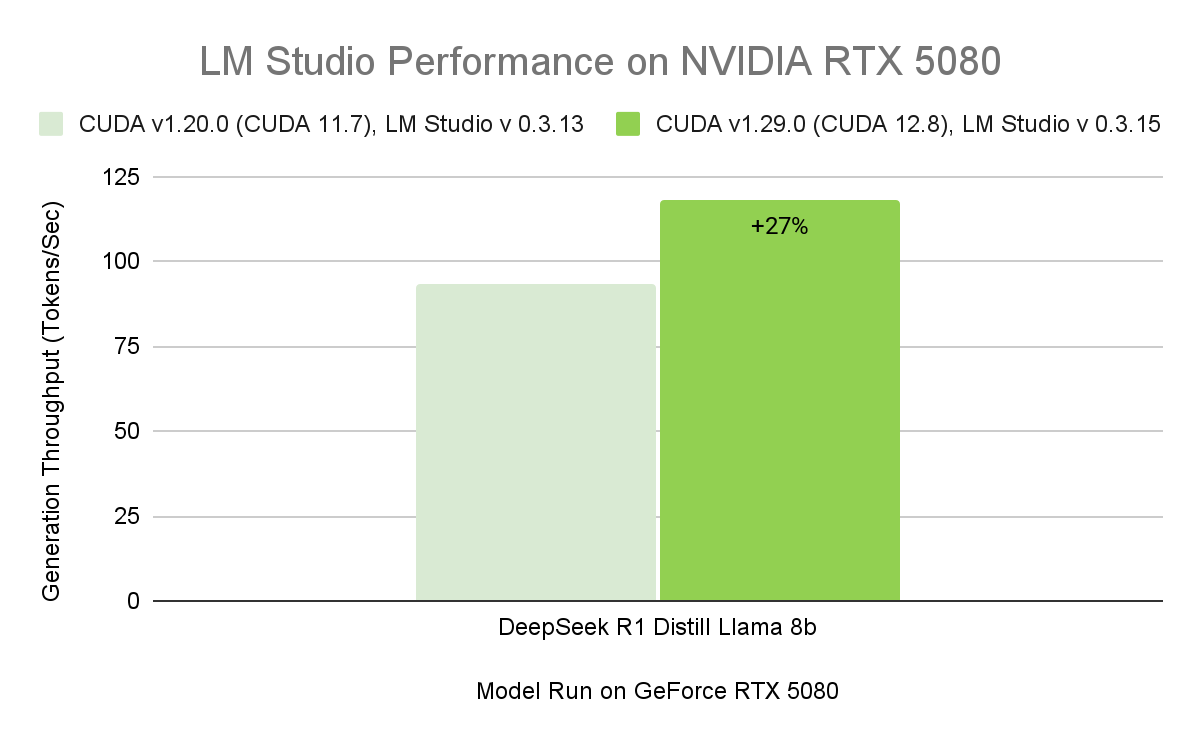
With a appropriate driver, LM Studio mechanically upgrades to the CUDA 12.8 runtime, enabling considerably sooner mannequin load instances and better general efficiency.
These enhancements ship smoother inference and sooner response instances throughout the total vary of RTX AI PCs — from skinny, gentle laptops to high-performance desktops and workstations.
Get Began With LM Studio
LM Studio is free to obtain and runs on Home windows, macOS and Linux. With the newest 0.3.15 launch and ongoing optimizations, customers can count on continued enhancements in efficiency, customization and value — making native AI sooner, extra versatile and extra accessible.
Customers can load a mannequin by way of the desktop chat interface or allow developer mode to reveal an OpenAI-compatible API.
To shortly get began, obtain the newest model of LM Studio and open up the appliance.
- Click on the magnifying glass icon on the left panel to open up the Uncover menu.
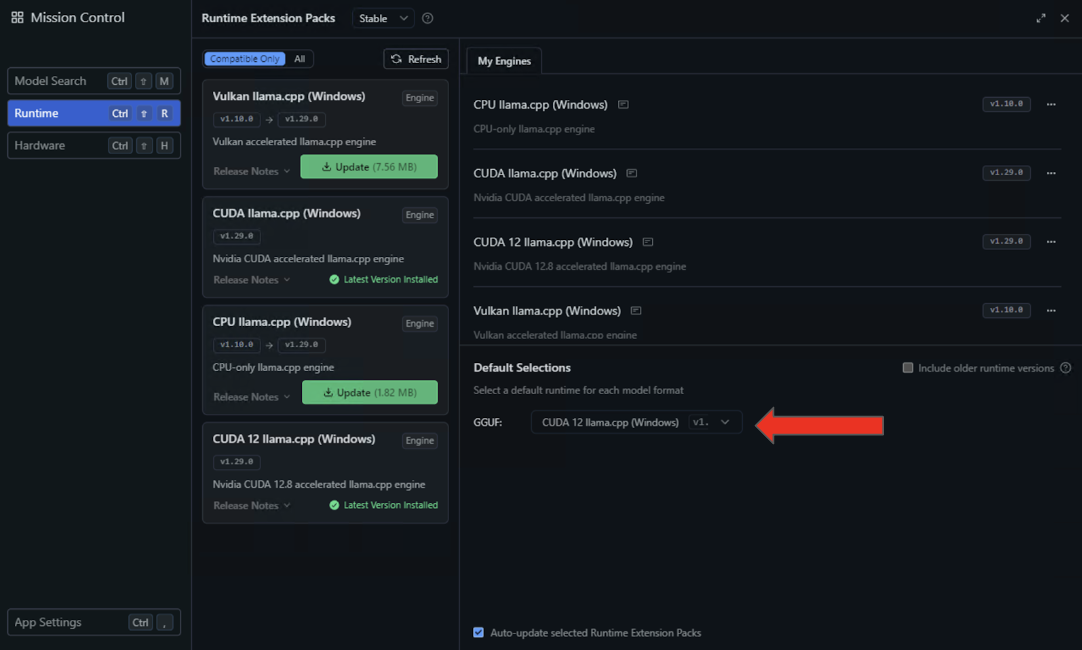
- Choose the Runtime settings on the left panel and seek for the CUDA 12 llama.cpp (Home windows) runtime within the availability checklist. Choose the button to Obtain and Set up.
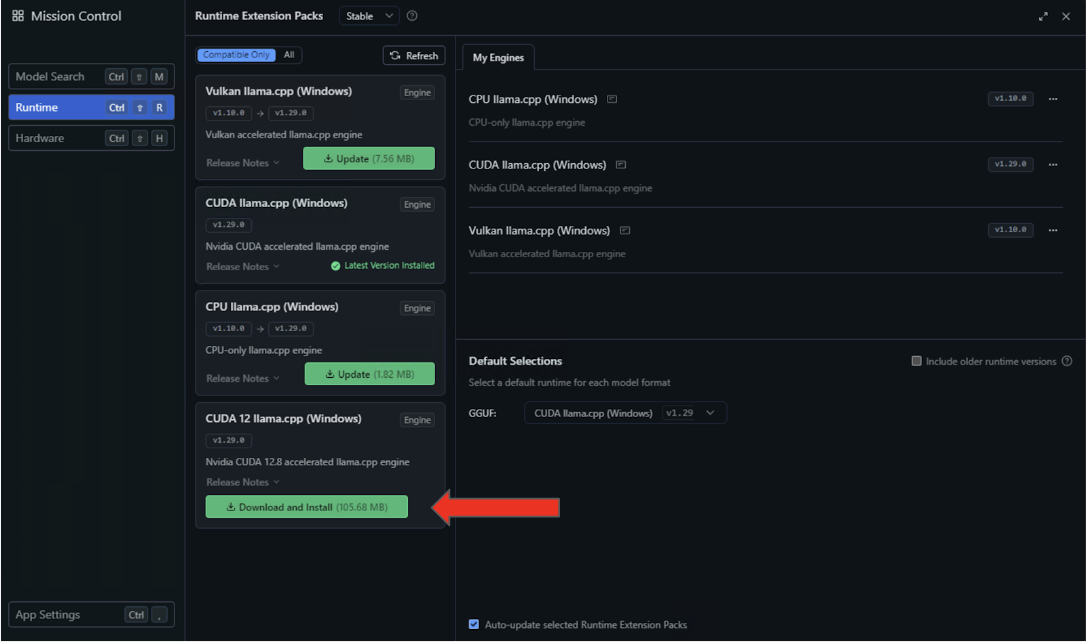
- After the set up completes, configure LM Studio to make use of this runtime by default by deciding on CUDA 12 llama.cpp (Home windows) within the Default Choices dropdown.
- For the ultimate steps in optimizing CUDA execution, load a mannequin in LM Studio and enter the Settings menu by clicking the gear icon to the left of the loaded mannequin.

- From the ensuing dropdown menu, toggle “Flash Consideration” to be on and offload all mannequin layers onto the GPU by dragging the “GPU Offload” slider to the suitable.
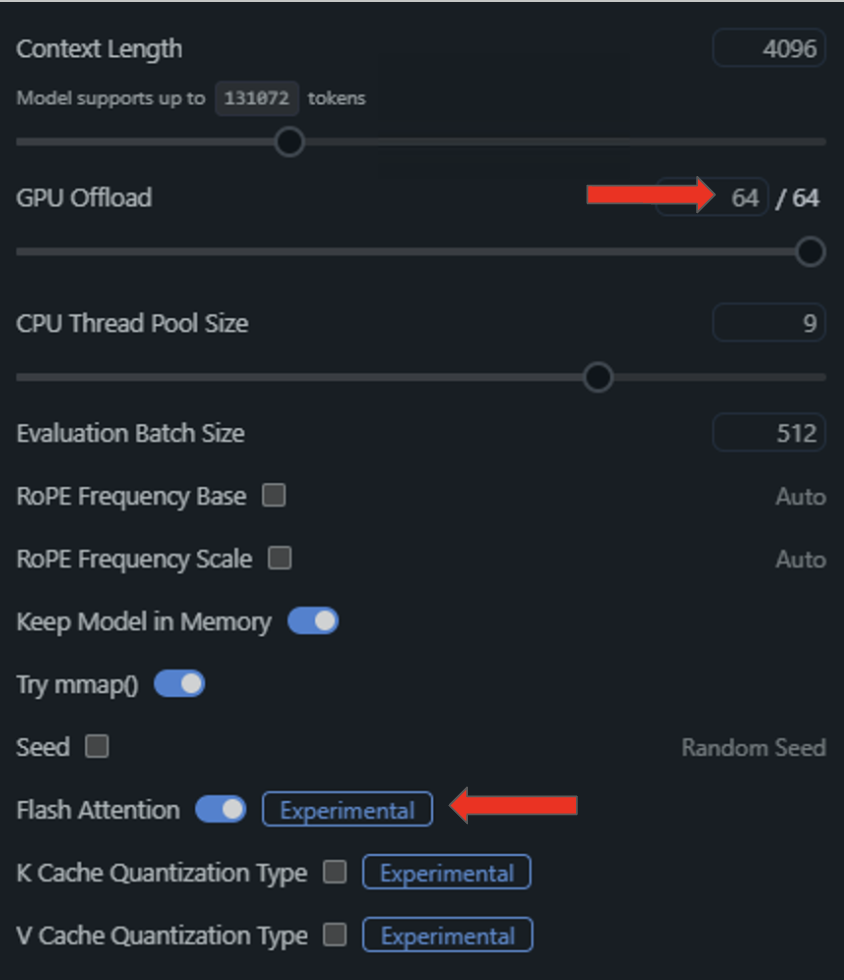
As soon as these options are enabled and configured, working NVIDIA GPU inference on a neighborhood setup is sweet to go.
LM Studio helps mannequin presets, a variety of quantization codecs and developer controls like tool_choice for fine-tuned inference. For these trying to contribute, the llama.cpp GitHub repository is actively maintained and continues to evolve with community- and NVIDIA-driven efficiency enhancements.
Every week, the RTX AI Storage weblog sequence options community-driven AI improvements and content material for these trying to study extra about NVIDIA NIM microservices and AI Blueprints, in addition to constructing AI brokers, artistic workflows, digital people, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.