- The highest 10 most clever open-source fashions all use a mixture-of-experts structure.
- Kimi K2 Considering, DeepSeek-R1, Mistral Massive 3 and others run 10x quicker on NVIDIA GB200 NVL72.
A glance below the hood of nearly any frontier mannequin right this moment will reveal a mixture-of-experts (MoE) mannequin structure that mimics the effectivity of the human mind.
Simply because the mind prompts particular areas primarily based on the duty, MoE fashions divide work amongst specialised “consultants,” activating solely the related ones for each AI token. This ends in quicker, extra environment friendly token technology with no proportional improve in compute.
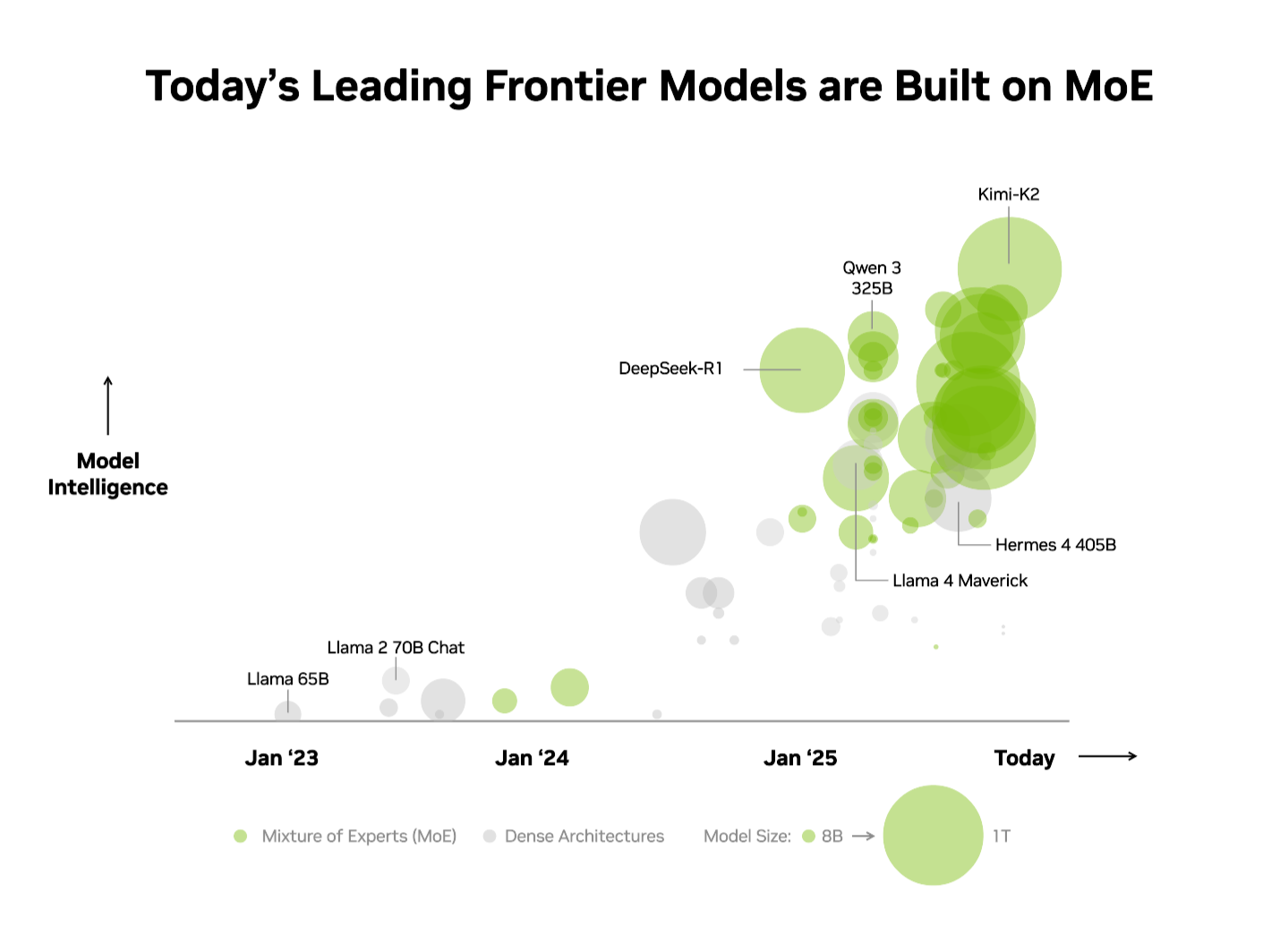
The business has already acknowledged this benefit. On the impartial Synthetic Evaluation (AA) leaderboard, the highest 10 most clever open-source fashions use an MoE structure, together with DeepSeek AI’s DeepSeek-R1, Moonshot AI’s Kimi K2 Considering, OpenAI’s gpt-oss-120B and Mistral AI’s Mistral Massive 3.
Nonetheless, scaling MoE fashions in manufacturing whereas delivering excessive efficiency is notoriously tough. The acute codesign of NVIDIA GB200 NVL72 methods combines {hardware} and software program optimizations for optimum efficiency and effectivity, making it sensible and easy to scale MoE fashions.
The Kimi K2 Considering MoE mannequin — ranked as probably the most clever open-source mannequin on the AA leaderboard — sees a 10x efficiency leap on the NVIDIA GB200 NVL72 rack-scale system in contrast with NVIDIA HGX H200. Constructing on the efficiency delivered for the DeepSeek-R1 and Mistral Massive 3 MoE fashions, this breakthrough underscores how MoE is changing into the structure of selection for frontier fashions — and why NVIDIA’s full-stack inference platform is the important thing to unlocking its full potential.
What Is MoE, and Why Has It Change into the Commonplace for Frontier Fashions?
Till lately, the business customary for constructing smarter AI was merely constructing larger, dense fashions that use all of their mannequin parameters — typically tons of of billions for right this moment’s most succesful fashions — to generate each token. Whereas highly effective, this strategy requires immense computing energy and power, making it difficult to scale.
Very similar to the human mind depends on particular areas to deal with completely different cognitive duties — whether or not processing language, recognizing objects or fixing a math downside — MoE fashions comprise a number of specialised “consultants.” For any given token, solely probably the most related ones are activated by a router. This design signifies that regardless that the general mannequin might include tons of of billions of parameters, producing a token entails utilizing solely a small subset — typically simply tens of billions.
By selectively partaking solely the consultants that matter most, MoE fashions obtain increased intelligence and adaptableness with no matching rise in computational value. This makes them the muse for environment friendly AI methods optimized for efficiency per greenback and per watt — producing considerably extra intelligence for each unit of power and capital invested.
Given these benefits, it’s no shock that MoE has quickly change into the structure of selection for frontier fashions, adopted by over 60% of open-source AI mannequin releases this 12 months. Since early 2023, it’s enabled a virtually 70x improve in mannequin intelligence — pushing the bounds of AI functionality.
“Our pioneering work with OSS mixture-of-experts structure, beginning with Mixtral 8x7B two years in the past, ensures superior intelligence is each accessible and sustainable for a broad vary of functions,” stated Guillaume Lample, cofounder and chief scientist at Mistral AI. “Mistral Massive 3’s MoE structure allows us to scale AI methods to better efficiency and effectivity whereas dramatically reducing power and compute calls for.”
Overcoming MoE Scaling Bottlenecks With Excessive Codesign
Frontier MoE fashions are just too massive and sophisticated to be deployed on a single GPU. To run them, consultants have to be distributed throughout a number of GPUs, a way referred to as professional parallelism. Even on highly effective platforms such because the NVIDIA H200, deploying MoE fashions entails bottlenecks resembling:
- Reminiscence limitations: For every token, GPUs should dynamically load the chosen consultants’ parameters from high-bandwidth reminiscence, inflicting frequent heavy strain on reminiscence bandwidth.
- Latency: Consultants should execute a near-instantaneous all-to-all communication sample to trade data and type a ultimate, full reply. Nonetheless, on H200, spreading consultants throughout greater than eight GPUs requires them to speak over higher-latency scale-out networking, limiting the advantages of professional parallelism.
The answer: excessive codesign.
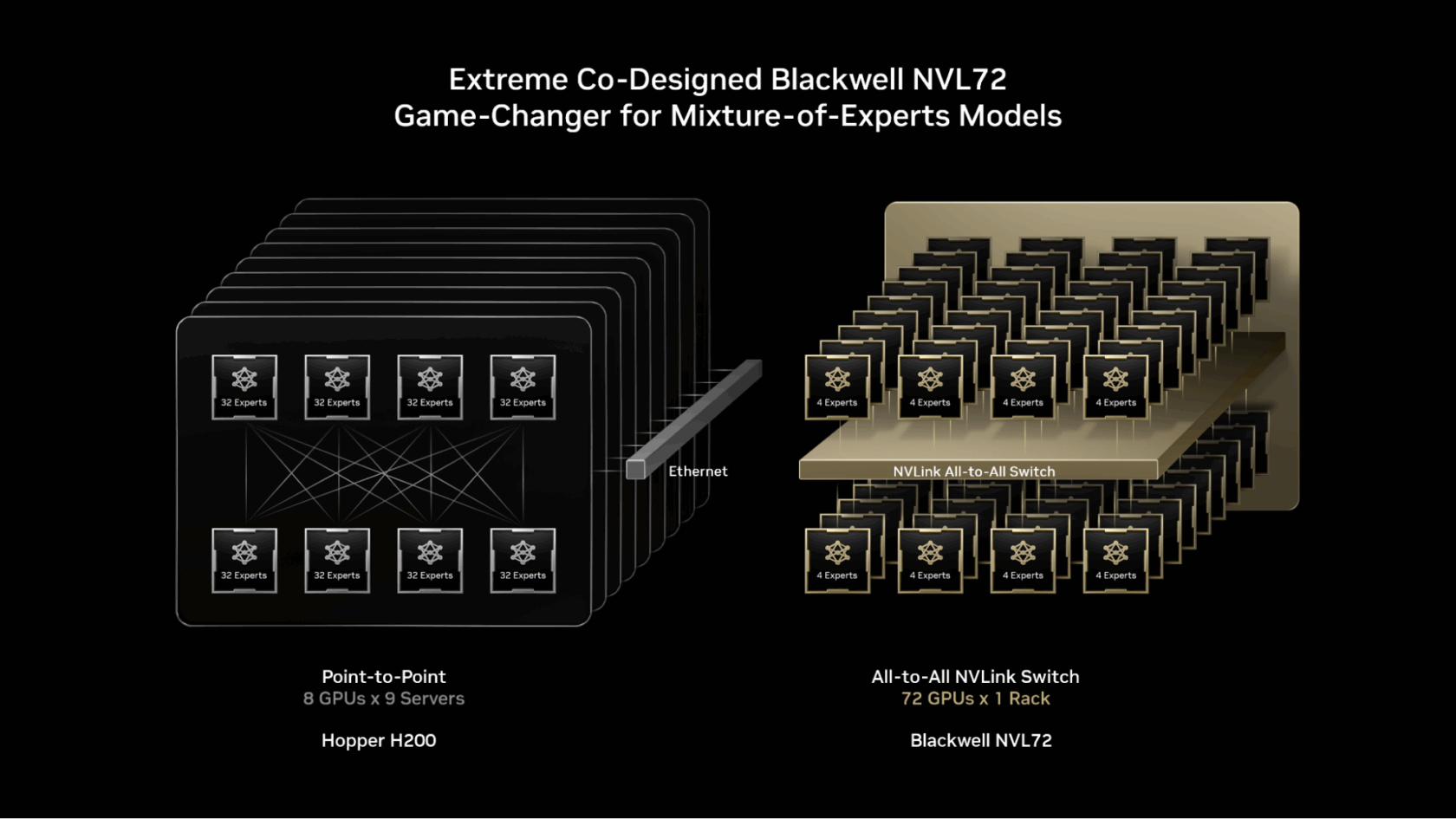
NVIDIA GB200 NVL72 is a rack-scale system with 72 NVIDIA Blackwell GPUs working collectively as in the event that they had been one, delivering 1.4 exaflops of AI efficiency and 30TB of quick shared reminiscence. The 72 GPUs are related utilizing NVLink Swap right into a single, huge NVLink interconnect cloth, which permits each GPU to speak with one another with 130 TB/s of NVLink connectivity.
MoE fashions can faucet into this design to scale professional parallelism far past earlier limits — distributing the consultants throughout a a lot bigger set of as much as 72 GPUs.
This architectural strategy immediately resolves MoE scaling bottlenecks by:
- Lowering the variety of consultants per GPU: Distributing consultants throughout as much as 72 GPUs reduces the variety of consultants per GPU, minimizing parameter-loading strain on every GPU’s high-bandwidth reminiscence. Fewer consultants per GPU additionally frees up reminiscence house, permitting every GPU to serve extra concurrent customers and assist longer enter lengths.
- Accelerating professional communication: Consultants unfold throughout GPUs can talk with one another immediately utilizing NVLink. The NVLink Swap additionally has the compute energy wanted to carry out among the calculations required to mix data from varied consultants, rushing up supply of the ultimate reply.
Different full-stack optimizations additionally play a key function in unlocking excessive inference efficiency for MoE fashions. The NVIDIA Dynamo framework orchestrates disaggregated serving by assigning prefill and decode duties to completely different GPUs, permitting decode to run with massive professional parallelism, whereas prefill makes use of parallelism methods higher suited to its workload. The NVFP4 format helps keep accuracy whereas additional boosting efficiency and effectivity.
Open-source inference frameworks resembling NVIDIA TensorRT-LLM, SGLang and vLLM assist these optimizations for MoE fashions. SGLang, specifically, has performed a major function in advancing large-scale MoE on GB200 NVL72, serving to validate and mature lots of the methods used right this moment.
To deliver this efficiency to enterprises worldwide, the GB200 NVL72 is being deployed by main cloud service suppliers and NVIDIA Cloud Companions together with Amazon Net Companies, Core42, CoreWeave, Crusoe, Google Cloud, Lambda, Microsoft Azure, Nebius, Nscale, Oracle Cloud Infrastructure, Collectively AI and others.
“At CoreWeave, our clients are leveraging our platform to place mixture-of-experts fashions into manufacturing as they construct agentic workflows,” stated Peter Salanki, cofounder and chief know-how officer at CoreWeave. “By working carefully with NVIDIA, we’re in a position to ship a tightly built-in platform that brings MoE efficiency, scalability and reliability collectively in a single place. You possibly can solely do this on a cloud purpose-built for AI.”
Clients resembling DeepL are utilizing Blackwell NVL72 rack-scale design to construct and deploy their next-generation AI fashions.
“DeepL is leveraging NVIDIA GB200 {hardware} to coach mixture-of-experts fashions, advancing its mannequin structure to enhance effectivity throughout coaching and inference, setting new benchmarks for efficiency in AI,” stated Paul Busch, analysis group lead at DeepL.
The Proof Is within the Efficiency Per Watt
NVIDIA GB200 NVL72 effectively scales complicated MoE fashions and delivers a 10x leap in efficiency per watt. This efficiency leap isn’t only a benchmark; it allows 10x the token income, reworking the economics of AI at scale in power- and cost-constrained knowledge facilities.
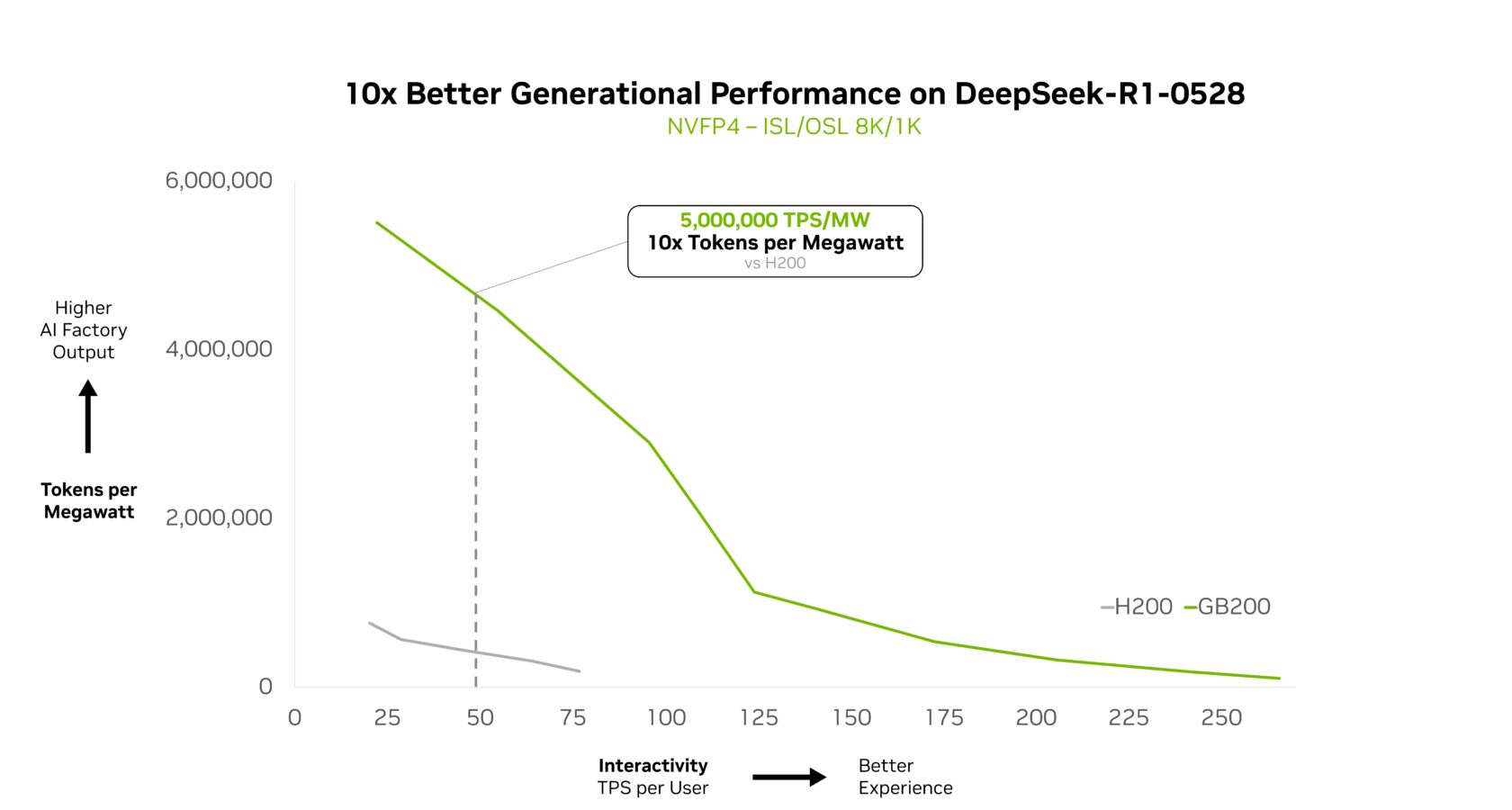
At NVIDIA GTC Washington, D.C., NVIDIA founder and CEO Jensen Huang highlighted how GB200 NVL72 delivers 10x the efficiency of NVIDIA Hopper for DeepSeek-R1, and this efficiency extends to different DeepSeek variants as effectively.
“With GB200 NVL72 and Collectively AI’s customized optimizations, we’re exceeding buyer expectations for large-scale inference workloads for MoE fashions like DeepSeek-V3,” stated Vipul Ved Prakash, cofounder and CEO of Collectively AI. “The efficiency good points come from NVIDIA’s full-stack optimizations coupled with Collectively AI Inference breakthroughs throughout kernels, runtime engine and speculative decoding.”
This efficiency benefit is clear throughout different frontier fashions.
Kimi K2 Considering, probably the most clever open-source mannequin, serves as one other proof level, reaching 10x higher generational efficiency when deployed on GB200 NVL72.
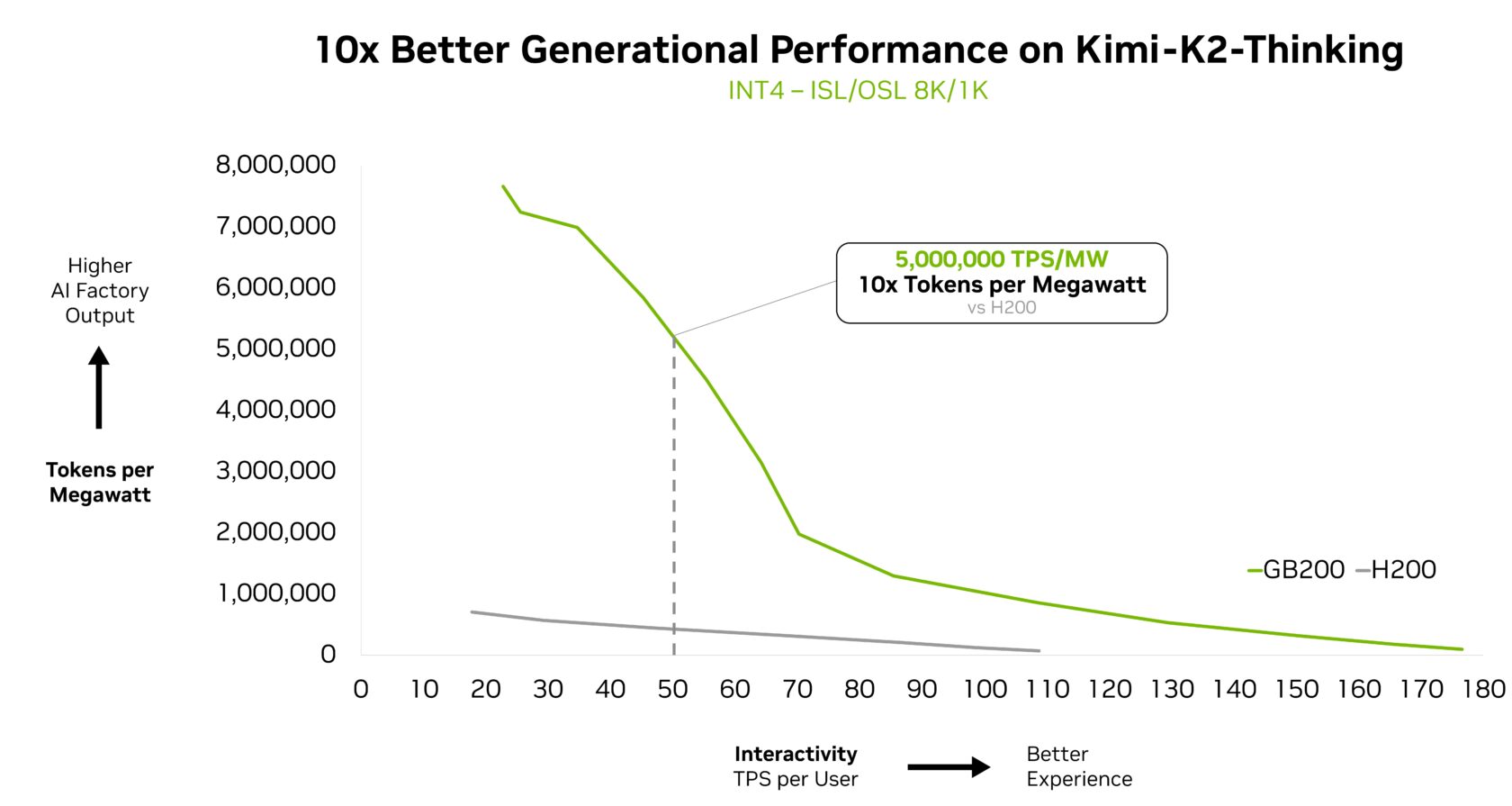
Fireworks AI has at present deployed Kimi K2 on the NVIDIA B200 platform to realize the highest efficiency on the Synthetic Evaluation leaderboard.
“NVIDIA GB200 NVL72 rack-scale design makes MoE mannequin serving dramatically extra environment friendly,” stated Lin Qiao, cofounder and CEO of Fireworks AI. “Wanting forward, NVL72 has the potential to rework how we serve huge MoE fashions, delivering main efficiency enhancements over the Hopper platform and setting a brand new bar for frontier mannequin pace and effectivity.”
Mistral Massive 3 additionally achieved a 10x efficiency achieve on the GB200 NVL72 in contrast with the prior-generation H200. This generational achieve interprets into higher consumer expertise, decrease per-token value and better power effectivity for this new MoE mannequin.
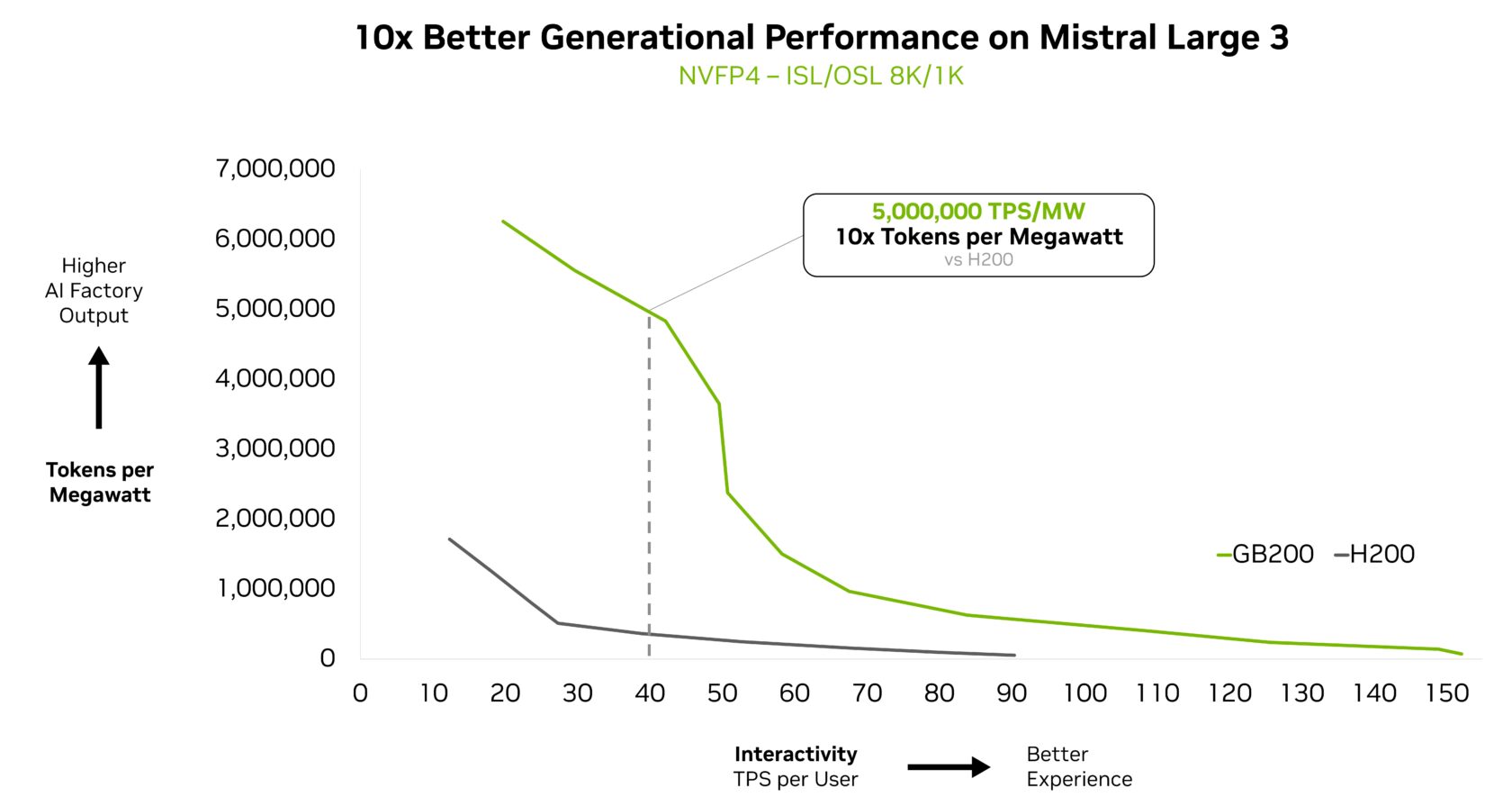
Powering Intelligence at Scale
The NVIDIA GB200 NVL72 rack-scale system is designed to ship robust efficiency past MoE fashions.
The explanation turns into clear when having a look at the place AI is heading: the latest technology of multimodal AI fashions have specialised elements for language, imaginative and prescient, audio and different modalities, activating solely those related to the duty at hand.
In agentic methods, completely different “brokers” focus on planning, notion, reasoning, instrument use or search, and an orchestrator coordinates them to ship a single consequence. In each circumstances, the core sample mirrors MoE: route every a part of the issue to probably the most related consultants, then coordinate their outputs to supply the ultimate consequence.
Extending this precept to manufacturing environments the place a number of functions and brokers serve a number of customers unlocks new ranges of effectivity. As a substitute of duplicating huge AI fashions for each agent or software, this strategy can allow a shared pool of consultants accessible to all, with every request routed to the correct professional.
Combination of consultants is a strong structure shifting the business towards a future the place huge functionality, effectivity and scale coexist. The GB200 NVL72 unlocks this potential right this moment, and NVIDIA’s roadmap with the NVIDIA Vera Rubin structure will proceed to increase the horizons of frontier fashions.
Study extra about how GB200 NVL72 scales complicated MoE fashions on this technical deep dive.
This publish is a part of Suppose SMART, a sequence targeted on how main AI service suppliers, builders and enterprises can enhance their inference efficiency and return on funding with the newest developments from NVIDIA’s full-stack inference platform.