Editor’s word: This put up is a part of the AI Decoded sequence, which demystifies AI by making the know-how extra accessible, and showcases new {hardware}, software program, instruments and accelerations for RTX PC customers.
Massive language fashions are driving a few of the most enjoyable developments in AI with their means to rapidly perceive, summarize and generate text-based content material.
These capabilities energy quite a lot of use circumstances, together with productiveness instruments, digital assistants, non-playable characters in video video games and extra. However they’re not a one-size-fits-all resolution, and builders usually should fine-tune LLMs to suit the wants of their functions.
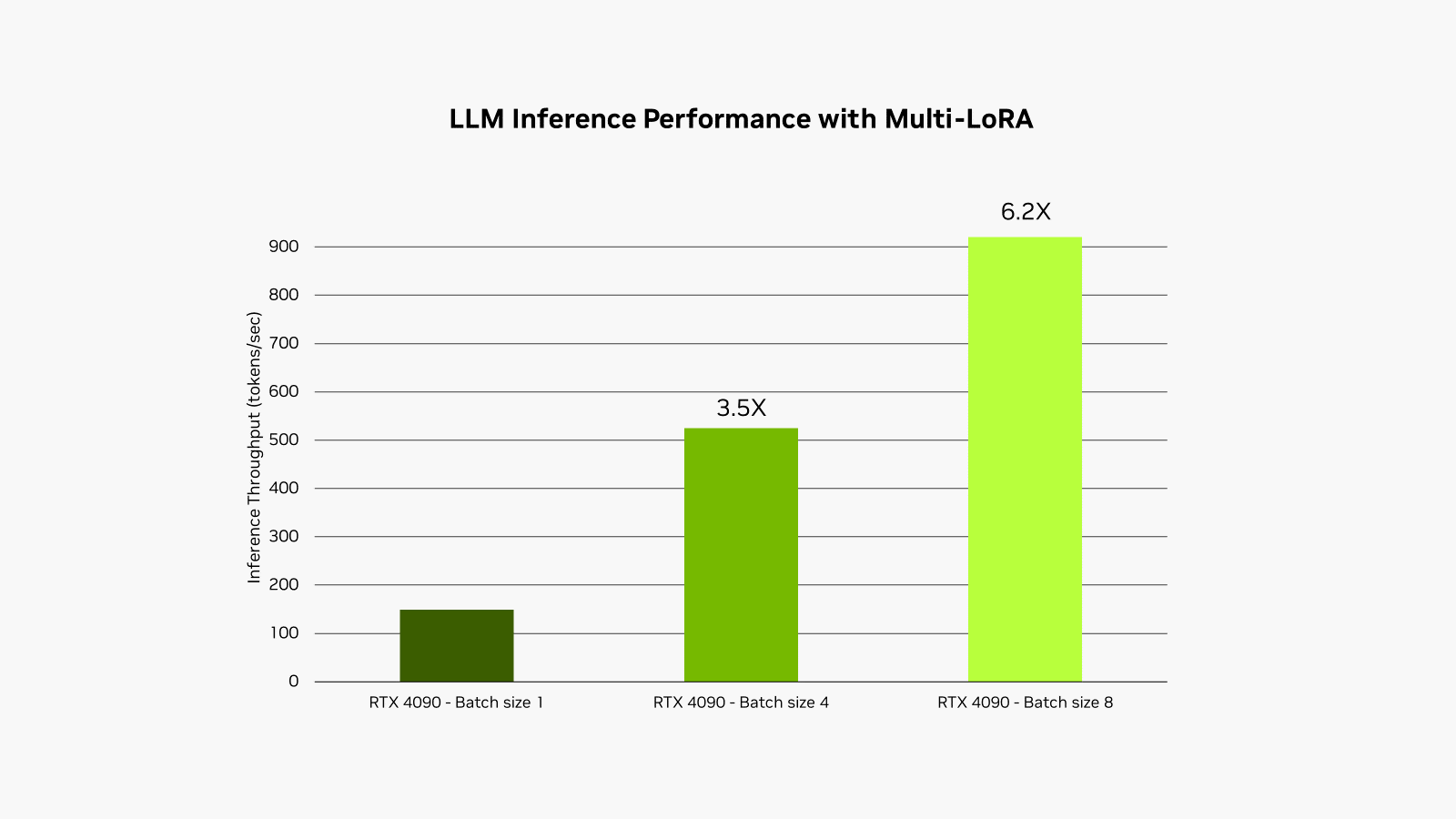
The NVIDIA RTX AI Toolkit makes it straightforward to fine-tune and deploy AI fashions on RTX AI PCs and workstations by way of a method referred to as low-rank adaptation, or LoRA. A brand new replace, obtainable right this moment, permits help for utilizing a number of LoRA adapters concurrently throughout the NVIDIA TensorRT-LLM AI acceleration library, enhancing the efficiency of fine-tuned fashions by as much as 6x.
Superb-Tuned for Efficiency
LLMs have to be fastidiously personalized to realize increased efficiency and meet rising person calls for.
These foundational fashions are educated on enormous quantities of knowledge however usually lack the context wanted for a developer’s particular use case. For instance, a generic LLM can generate online game dialogue, however it can doubtless miss the nuance and subtlety wanted to put in writing within the fashion of a woodland elf with a darkish previous and a barely hid disdain for authority.
To realize extra tailor-made outputs, builders can fine-tune the mannequin with info associated to the app’s use case.
Take the instance of growing an app to generate in-game dialogue utilizing an LLM. The method of fine-tuning begins with utilizing the weights of a pretrained mannequin, akin to info on what a personality might say within the sport. To get the dialogue in the fitting fashion, a developer can tune the mannequin on a smaller dataset of examples, akin to dialogue written in a extra spooky or villainous tone.
In some circumstances, builders might need to run all of those completely different fine-tuning processes concurrently. For instance, they could need to generate advertising copy written in several voices for numerous content material channels. On the similar time, they could need to summarize a doc and make stylistic strategies — in addition to draft a online game scene description and imagery immediate for a text-to-image generator.
It’s not sensible to run a number of fashions concurrently, as they received’t all slot in GPU reminiscence on the similar time. Even when they did, their inference time can be impacted by reminiscence bandwidth — how briskly information will be learn from reminiscence into GPUs.
Lo(RA) and Behold
A preferred method to handle these points is to make use of fine-tuning methods akin to low-rank adaptation. A easy mind-set of it’s as a patch file containing the customizations from the fine-tuning course of.
As soon as educated, personalized LoRA adapters can combine seamlessly with the muse mannequin throughout inference, including minimal overhead. Builders can connect the adapters to a single mannequin to serve a number of use circumstances. This retains the reminiscence footprint low whereas nonetheless offering the extra particulars wanted for every particular use case.
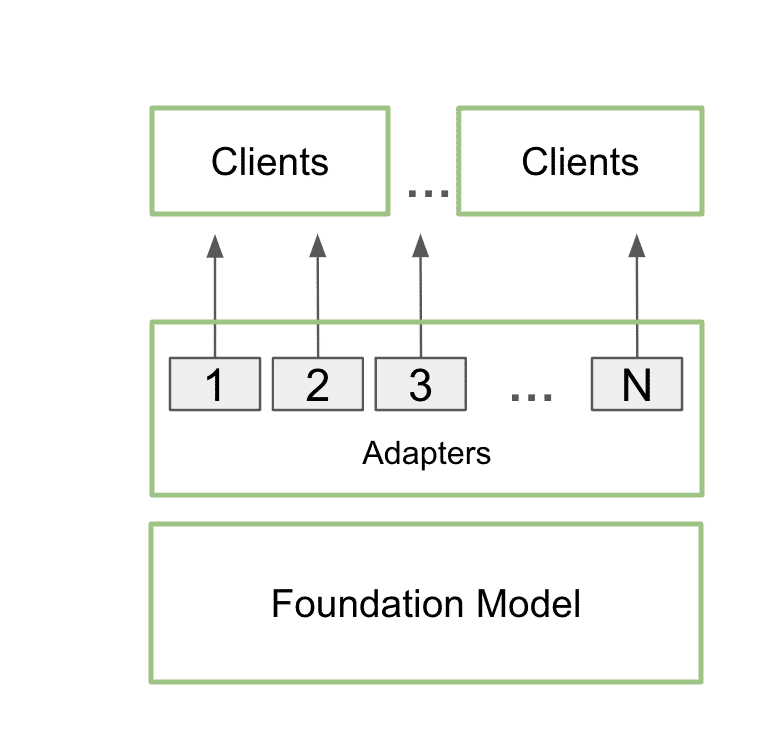
In apply, which means an app can preserve only one copy of the bottom mannequin in reminiscence, alongside many customizations utilizing a number of LoRA adapters.
This course of is known as multi-LoRA serving. When a number of calls are made to the mannequin, the GPU can course of all the calls in parallel, maximizing the usage of its Tensor Cores and minimizing the calls for of reminiscence and bandwidth so builders can effectively use AI fashions of their workflows. Superb-tuned fashions utilizing multi-LoRA adapters carry out as much as 6x sooner.
Within the instance of the in-game dialogue utility described earlier, the app’s scope could possibly be expanded, utilizing multi-LoRA serving, to generate each story components and illustrations — pushed by a single immediate.
The person might enter a primary story concept, and the LLM would flesh out the idea, increasing on the concept to supply an in depth basis. The appliance might then use the identical mannequin, enhanced with two distinct LoRA adapters, to refine the story and generate corresponding imagery. One LoRA adapter generates a Steady Diffusion immediate to create visuals utilizing a regionally deployed Steady Diffusion XL mannequin. In the meantime, the opposite LoRA adapter, fine-tuned for story writing, might craft a well-structured and interesting narrative.
On this case, the identical mannequin is used for each inference passes, making certain that the house required for the method doesn’t considerably enhance. The second go, which entails each textual content and picture era, is carried out utilizing batched inference, making the method exceptionally quick and environment friendly on NVIDIA GPUs. This enables customers to quickly iterate by way of completely different variations of their tales, refining the narrative and the illustrations with ease.
This course of is printed in additional element in a current technical weblog.
LLMs have gotten one of the crucial vital elements of recent AI. As adoption and integration grows, demand for highly effective, quick LLMs with application-specific customizations will solely enhance. The multi-LoRA help added right this moment to the RTX AI Toolkit provides builders a robust new method to speed up these capabilities.