Many customers need to run massive language fashions (LLMs) regionally for extra privateness and management, and with out subscriptions, however till not too long ago, this meant a trade-off in output high quality. Newly launched open-weight fashions, like OpenAI’s gpt-oss and Alibaba’s Qwen 3, can run immediately on PCs, delivering helpful high-quality outputs, particularly for native agentic AI.
This opens up new alternatives for college kids, hobbyists and builders to discover generative AI purposes regionally. NVIDIA RTX PCs speed up these experiences, delivering quick and snappy AI to customers.
Getting Began With Native LLMs Optimized for RTX PCs
NVIDIA has labored to optimize high LLM purposes for RTX PCs, extracting most efficiency of Tensor Cores in RTX GPUs.
One of many best methods to get began with AI on a PC is with Ollama, an open-source device that gives a easy interface for operating and interacting with LLMs. It helps the flexibility to tug and drop PDFs into prompts, conversational chat and multimodal understanding workflows that embrace textual content and pictures.
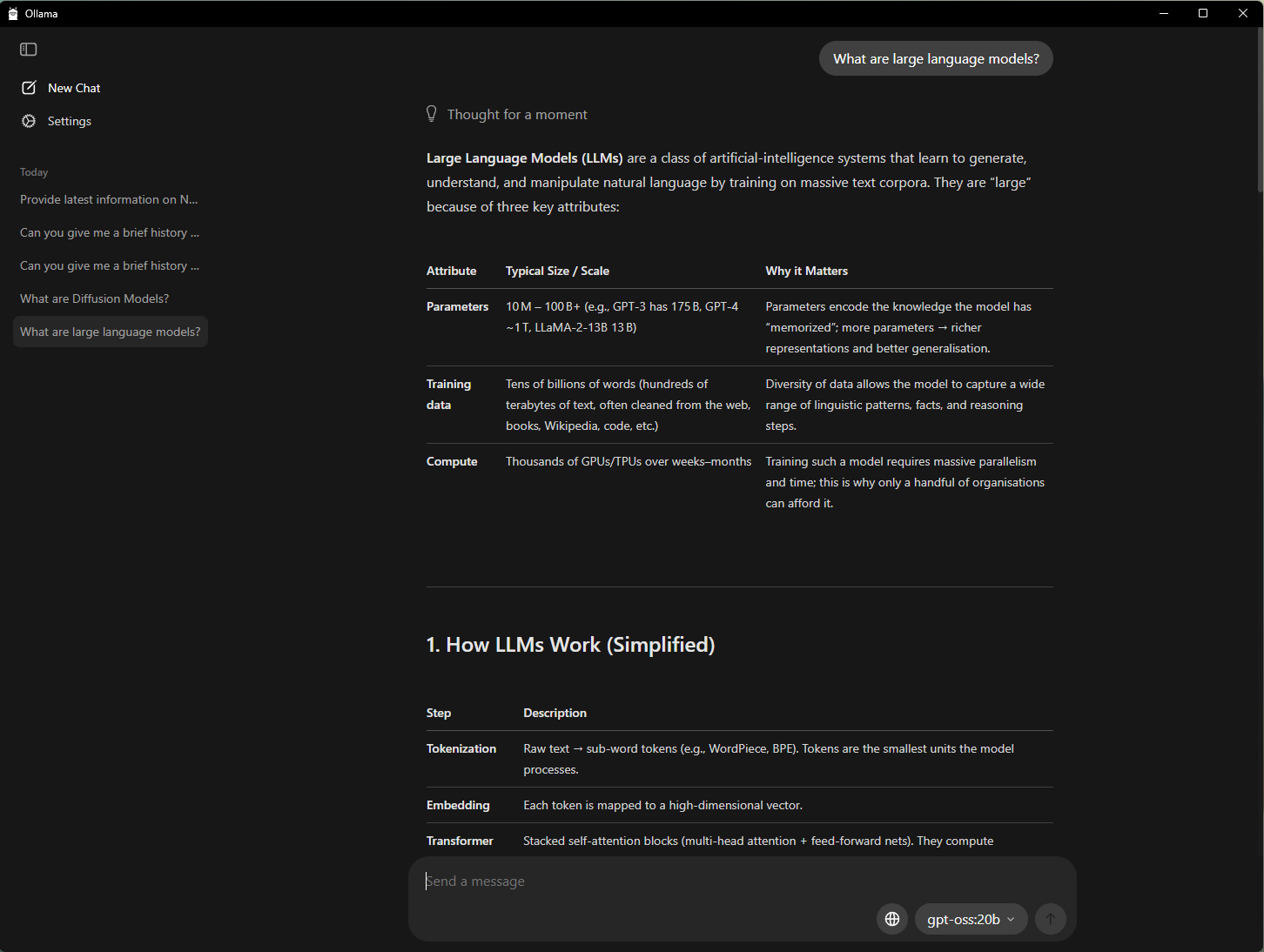
NVIDIA has collaborated with Ollama to enhance its efficiency and person expertise. The newest developments embrace:
- Efficiency enhancements on GeForce RTX GPUs for OpenAI’s gpt-oss-20B mannequin and Google’s Gemma 3 fashions
- Help for the brand new Gemma 3 270M and EmbeddingGemma3 fashions for hyper-efficient retrieval-augmented technology on the RTX AI PC
- Improved mannequin scheduling system to maximise and precisely report reminiscence utilization
- Stability and multi-GPU enhancements
Ollama is a developer framework that can be utilized with different purposes. For instance, AnythingLLM — an open-source app that lets customers construct their very own AI assistants powered by any LLM — can run on high of Ollama and profit from all of its accelerations.
Lovers may also get began with native LLMs utilizing LM Studio, an app powered by the favored llama.cpp framework. The app offers a user-friendly interface for operating fashions regionally, letting customers load completely different LLMs, chat with them in actual time and even serve them as native utility programming interface endpoints for integration into customized initiatives.
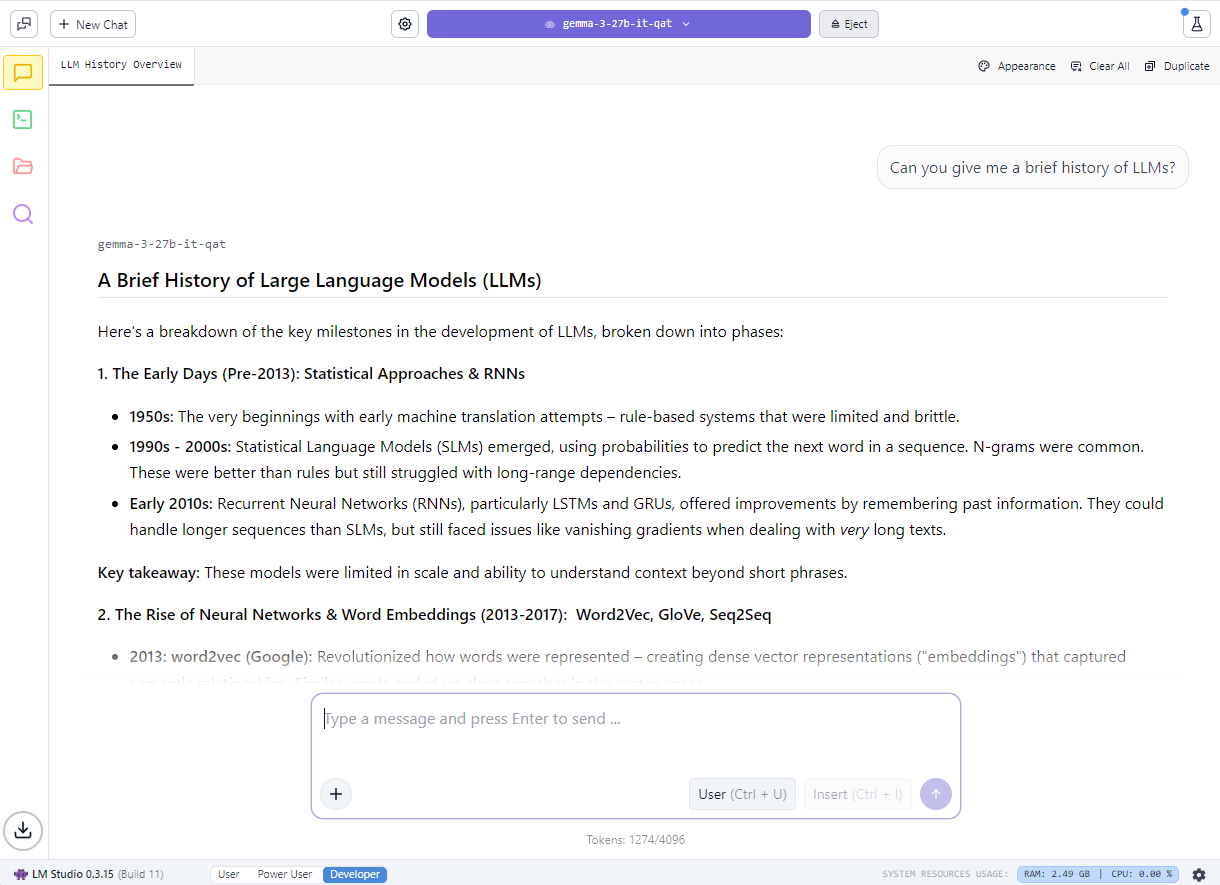
NVIDIA has labored with llama.cpp to optimize efficiency on NVIDIA RTX GPUs. The most recent updates embrace:
- Help for the most recent NVIDIA Nemotron Nano v2 9B mannequin, which relies on the novel hybrid-mamba structure
- Flash Consideration now turned on by default, providing an as much as 20% efficiency enchancment in contrast with Flash Consideration being turned off
- CUDA kernels optimizations for RMS Norm and fast-div based mostly modulo, leading to as much as 9% efficiency enhancements for widespread mannequin
- Semantic versioning, making it simple for builders to undertake future releases
Study extra about gpt-oss on RTX and the way NVIDIA has labored with LM Studio to speed up LLM efficiency on RTX PCs.
Creating an AI-Powered Examine Buddy With AnythingLLM
Along with larger privateness and efficiency, operating LLMs regionally removes restrictions on what number of recordsdata could be loaded or how lengthy they keep out there, enabling context-aware AI conversations for an extended time frame. This creates extra flexibility for constructing conversational and generative AI-powered assistants.
For college students, managing a flood of slides, notes, labs and previous exams could be overwhelming. Native LLMs make it attainable to create a private tutor that may adapt to particular person studying wants.
The demo under exhibits how college students can use native LLMs to construct a generative-AI powered assistant:
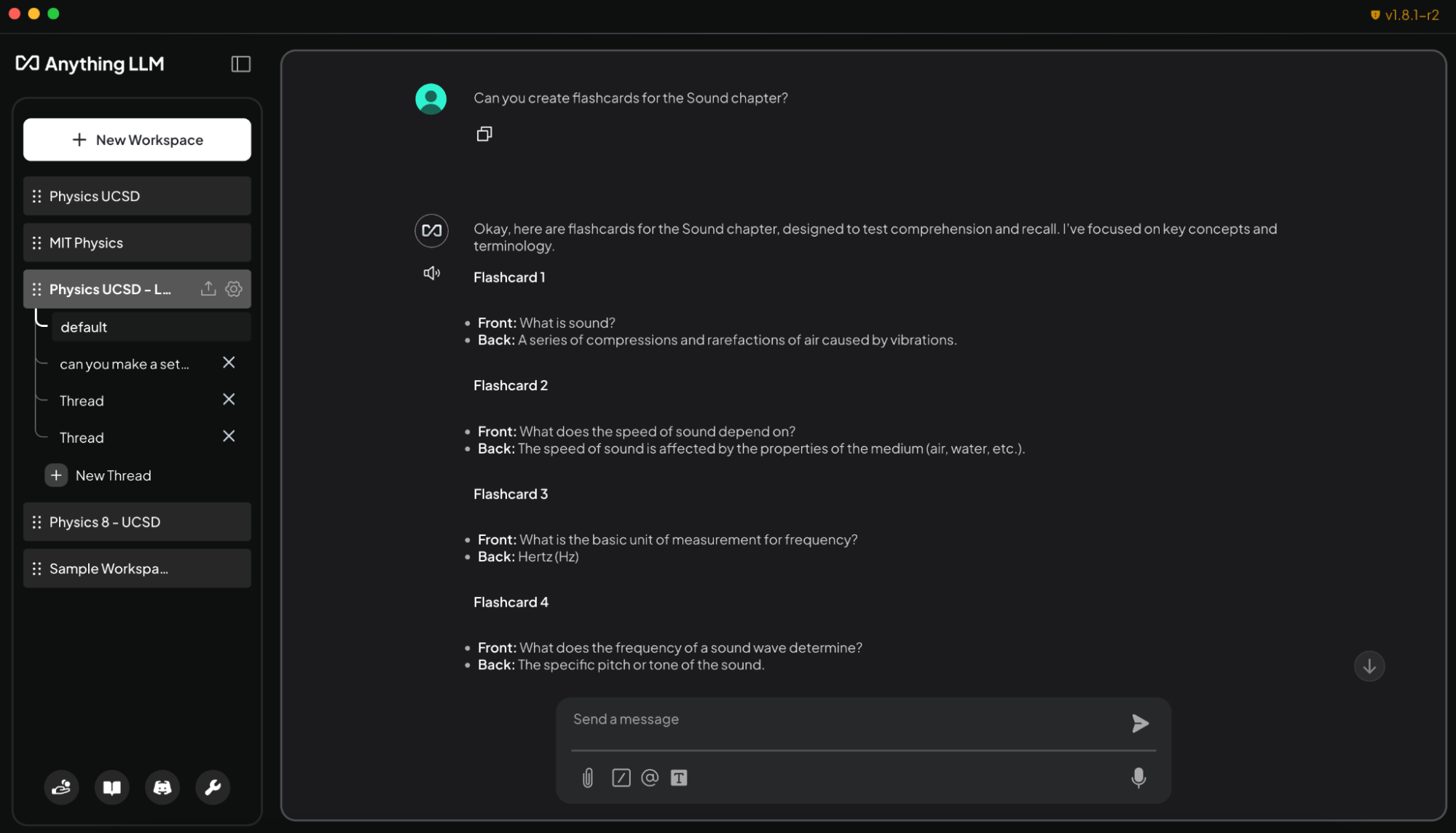
A easy method to do that is with AnythingLLM, which helps doc uploads, customized information bases and conversational interfaces. This makes it a versatile device for anybody who needs to create a customizable AI to assist with analysis, initiatives or day-to-day duties. And with RTX acceleration, customers can expertise even quicker responses.
By loading syllabi, assignments and textbooks into AnythingLLM on RTX PCs, college students can achieve an adaptive, interactive examine companion. They will ask the agent, utilizing plain textual content or speech, to assist with duties like:
- Producing flashcards from lecture slides: “Create flashcards from the Sound chapter lecture slides. Put key phrases on one aspect and definitions on the opposite.”
- Asking contextual questions tied to their supplies: “Clarify conservation of momentum utilizing my Physics 8 notes.”
- Creating and grading quizzes for examination prep: “Create a 10-question a number of alternative quiz based mostly on chapters 5-6 of my chemistry textbook and grade my solutions.”
- Strolling by way of powerful issues step-by-step: “Present me the right way to clear up downside 4 from my coding homework, step-by-step.”
Past the classroom, hobbyists and professionals can use AnythingLLM to arrange for certifications in new fields of examine or for different related functions. And operating regionally on RTX GPUs ensures quick, non-public responses with no subscription prices or utilization limits.
Venture G-Help Can Now Management Laptop computer Settings
Venture G-Help is an experimental AI assistant that helps customers tune, management and optimize their gaming PCs by way of easy voice or textual content instructions — with no need to dig by way of menus. Over the following day, a brand new G-Help replace will roll out by way of the house web page of the NVIDIA App.
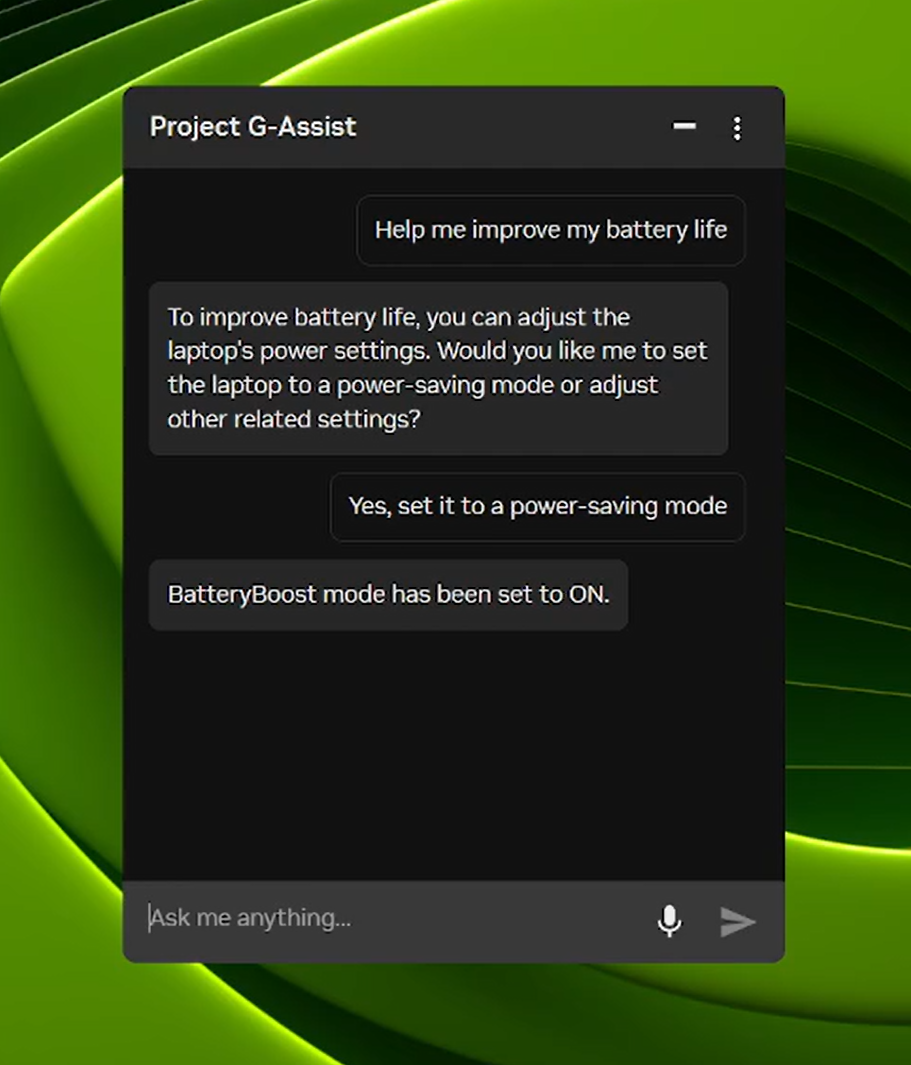
Constructing on its new, extra environment friendly AI mannequin and help for almost all of RTX GPUs launched in August, the brand new G-Help replace provides instructions to regulate laptop computer settings, together with:
- App profiles optimized for laptops: Mechanically regulate video games or apps for effectivity, high quality or a stability when laptops aren’t linked to chargers.
- BatteryBoost management: Activate or regulate BatteryBoost to increase battery life whereas conserving body charges easy.
- WhisperMode management: Minimize fan noise by as much as 50% when wanted, and return to full efficiency when not.
Venture G-Help can be extensible. With the G-Help Plug-In Builder, customers can create and customise G-Help performance by including new instructions or connecting exterior instruments with easy-to-create plugins. And with the G-Help Plug-In Hub, customers can simply uncover and set up plug-ins to develop G-Help capabilities.
Try NVIDIA’s G-Help GitHub repository for supplies on the right way to get began, together with pattern plug-ins, step-by-step directions and documentation for constructing customized functionalities.
#ICYMI — The Newest Developments in RTX AI PCs
🎉Ollama Will get a Main Efficiency Enhance on RTX
Newest updates embrace optimized efficiency for OpenAI’s gpt-oss-20B, quicker Gemma 3 fashions and smarter mannequin scheduling to scale back reminiscence points and enhance multi-GPU effectivity.
🚀 Llama.cpp and GGML Optimized for RTX
The most recent updates ship quicker, extra environment friendly inference on RTX GPUs, together with help for the NVIDIA Nemotron Nano v2 9B mannequin, Flash Consideration enabled by default and CUDA kernel optimizations.
⚡Venture G-Help Replace Rolls Out
Obtain the G-Help v0.1.18 replace by way of the NVIDIA App. The replace options new instructions for laptop computer customers and enhanced reply high quality.
⚙️ Home windows ML With NVIDIA TensorRT for RTX Now Geneally Out there
Microsoft launched Home windows ML with NVIDIA TensorRT for RTX acceleration, delivering as much as 50% quicker inference, streamlined deployment and help for LLMs, diffusion and different mannequin varieties on Home windows 11 PCs.
🌐 NVIDIA Nemotron Powers AI Improvement
The NVIDIA Nemotron assortment of open fashions, datasets and strategies is fueling innovation in AI, from generalized reasoning to industry-specific purposes.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC publication.
Observe NVIDIA Workstation on LinkedIn and X.
See discover concerning software program product info.